TL;DR
- 외부 시스템의 장애가 우리 시스템까지 무너뜨리는 것을 막으려면 어떻게 해야 할까?
- 전기 회로 차단기에서 배우는 분산 시스템 설계 원칙과, Circuit Breaker의 3가지 상태가 존재하는 이유, 그리고 정답이 없는 임계값 설정의 딜레마를 다룬다.
1. 프롤로그: 한 번의 장애가 전체를 무너뜨릴 때
이커머스 서비스에서 연동하는 PG(Payment Gateway) 시스템이 응답하지 않기 시작하면 어떻게 될까요?
"타임아웃 설정해뒀으니까 1초 후에 실패 처리되겠지." 안심 하실 수 있습니다.하지만 예상과 달리, 상황은 점점 악화될 수 있습니다.
시간이 지나 PG가 복구된 후에도 서비스는 여전히 응답하지 않을 수 있습니다. 예를 들어 모든 스레드가 PG 응답을 기다리며 블로킹되어 있고, 새로운 요청은 대기열에서 무한정 기다리고 있을 수 있습니다.
분명히 타임아웃은 1초로 설정해두었습니다. 그런데 왜 이런 일이 벌어진 걸까요?
문제는 간단한 산술에 있었습니다. 타임아웃이 1초라고 해도, 동시에 200개의 요청이 들어오면 모든 스레드가 각각 1초씩 블로킹됩니다. 그 사이에 새로운 요청들이 계속 쌓입니다. 즉, 실패한 요청조차도 실패하기까지 리소스를 점유한다는 사실을 간과했던 것입니다.

타임아웃은 "개별 요청이 언제 포기할지"를 정할 뿐, "시스템 전체가 얼마나 많은 실패를 감당할 수 있는지"와는 별개의 문제입니다. 실패를 "빨리" 알아차리는 것도 중요하지만, 실패가 "확산"되는 것을 막는 별도의 메커니즘이 필요합니다. 그리고 그 해답이 바로 Circuit Breaker입니다.
2. 전기 회로 차단기의 작동 원리
가정집의 전기 차단기는 어떻게 동작할까요? 평상시에는 전류가 정상적으로 흐릅니다. 차단기는 회로에 연결되어 있지만, 전류의 흐름을 방해하지 않습니다. 그러다가 누전이 발생하거나 과전류가 흐르면, 차단기 내부의 감지 장치가 이를 인식합니다. 일정 수치 이상의 비정상적인 전류가 감지되면, 차단기는 물리적으로 회로를 끊어버립니다.
왜 끊을까요? 문제가 있는 회로에 계속 전류를 보내면 더 큰 피해가 발생하기 때문입니다. 전선이 과열되어 화재가 날 수도 있고, 사람이 감전될 수도 있습니다. 차단기는 "일단 끊고 보는" 안전 우선 설계를 구현한 것입니다.
여기서 중요한 점은 차단기가 문제를 해결하는 게 아니라 "피해 확산을 막는다"는 것입니다. 누전된 배선을 차단기가 고쳐주지는 않습니다. 하지만 누전으로 인해 집 전체가 불타는 것은 막아줍니다.
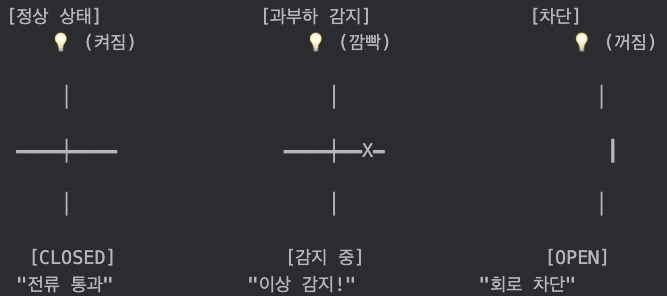
분산 시스템의 Circuit Breaker도 정확히 같은 철학을 따릅니다. 과전류는 과도한 실패율에 대응하고, 회로 차단은 요청 차단에 대응합니다. 그리고 화재 방지는 시스템 전체 다운 방지에 대응합니다. 전기 차단기가 집을 보호하듯, Circuit Breaker는 서비스를 보호합니다.
3. 분산 시스템에서의 "과전류"란 무엇인가?
3.1 Timeout만으로는 부족하다
많은 개발자들이 외부 시스템 연동 시 타임아웃 설정만으로 충분하다고 생각합니다. 실제로 처음에는 이렇게 설정했습니다.
feign:
client:
config:
pg-client:
connectTimeout: 500 # PG 연결 타임아웃 (ms)
readTimeout: 1000 # PG 응답 대기 타임아웃 (ms)
연결에 500ms, 응답 대기에 1초. 언뜻 보면 합리적인 설정입니다. PG 시스템의 정상 응답 시간이 100~500ms라는 것을 알고 있었기 때문에, 1초면 충분한 여유를 둔 것처럼 보였습니다.
하지만 문제는 타임아웃이 "발동"하기 전까지 일어나는 일에 있었습니다.
PG 시스템이 완전히 다운된 게 아니라 "느려진" 상황을 생각해봅시다. 응답 시간이 정상 500ms에서 갑자기 800ms, 900ms로 늘어납니다. 타임아웃 1초에는 걸리지 않지만, 처리량은 급격히 떨어집니다.
정상 상황:
- 응답 시간: 500ms
- 스레드 1개가 1초에 처리하는 요청: 2개
- 200개 스레드의 1초 처리량: 400개
지연 상황:
- 응답 시간: 900ms
- 스레드 1개가 1초에 처리하는 요청: 1.1개
- 200개 스레드의 1초 처리량: 220개
→ 처리량 45% 감소, 하지만 타임아웃은 발동하지 않음
더 심각한 경우를 생각해봅시다. PG 시스템이 응답을 아예 하지 않은경우, 모든 요청이 1초씩 기다린 후 타임아웃으로 실패합니다.
시나리오: PG 서버 완전 무응답
0초: 50개 요청 도착 → 50개 스레드 블로킹 시작
0.5초: 50개 추가 요청 → 100개 스레드 블로킹
1초:
- 처음 50개 타임아웃으로 실패 반환
- 새로운 50개 요청 도착 → 다시 100개 스레드 블로킹
1.5초: 50개 추가 요청 → 150개 스레드 블로킹
2초:
- 0.5초에 들어온 50개 타임아웃 실패
- 새로운 50개 요청 도착
...반복...
결국 실패하는 요청도 실패하기까지 리소스를 점유합니다. 타임아웃은 "얼마나 기다릴지"를 정할 뿐, "실패가 누적되는 것을 막아주지는 않습니다."
3.2 실패를 "빨리" 알아차리는 것 vs "확산"을 막는 것
타임아웃과 Circuit Breaker는 서로 다른 문제를 해결합니다. 타임아웃은 "이 요청이 얼마나 기다릴지"를 결정하고, Circuit Breaker는 "이미 실패가 반복되고 있으니 더 이상 시도하지 말자"를 결정합니다.
둘의 차이를 비유하자면 이렇습니다. 타임아웃은 "5분 기다려도 버스가 안 오면 택시 타자"이고, Circuit Breaker는 "이 버스 노선은 오늘 파업 중이니까 아예 정류장에 가지 말자"입니다. 전자는 개별 시도에 대한 인내심의 한계이고, 후자는 시스템 전체의 상황 판단입니다.
Circuit Breaker가 없다면, 외부 시스템이 장애 상태일 때 모든 요청이 타임아웃까지 기다린 후 실패합니다. 100개의 요청이 들어오면 100개 모두 1초씩 기다리며 스레드를 점유합니다. Circuit Breaker가 있다면, 실패가 일정 횟수 이상 반복되면 더 이상 시도하지 않고 즉시 실패를 반환합니다. 기다리는 시간 없이 밀리초 단위로 실패 응답을 받을 수 있습니다.
이것이 바로 "Fail Fast" 원칙입니다. 실패할 것이 뻔한 요청에 리소스를 낭비하지 않는 것입니다.
3.3 Cascade Failure: 실패의 전파
외부 시스템 장애가 정말 무서운 이유는 전파(Cascade)되기 때문입니다.
서비스 구조를 단순화하면 이렇습니다.
[사용자] → [주문 서비스] → [PG 시스템]
↓
[상품 서비스]
↓
[재고 서비스]
PG 시스템에 장애가 발생하면 어떻게 될까요?
1단계 - PG 호출 지연:
결제 요청들이 타임아웃까지 대기하고, 주문 서비스의 스레드 풀 점유율이 상승합니다.
2단계 - 주문 서비스 과부하:
스레드 풀이 고갈되기 시작합니다. 새로운 요청들이 대기열에 쌓이고, 상품 조회나 재고 확인 등 다른 요청도 처리할 수 없게 됩니다.
3단계 - 연쇄 장애:
주문 서비스가 응답하지 않으니 프론트엔드에서 타임아웃이 발생합니다. 사용자들이 새로고침을 하면 요청이 더 증가하고 상황은 악화됩니
다.
4단계 - 전체 시스템 다운:
DB 커넥션 풀까지 영향을 받고, 심지어 로그 적재도 밀리기 시작합니다. 복구 시도조차 어려워집니다.
[PG 장애]
│
▼
[결제 요청 타임아웃 대기]
│
▼
[주문 서비스 스레드 고갈]
╱ ╲
▼ ▼
[상품 조회 불가] [재고 확인 불가]
╲ ╱
▼ ▼
[전체 주문 기능 마비]
│
▼
[사용자 이탈 / 매출 손실]
핵심은 이것입니다. PG 시스템의 장애가 우리 시스템까지 끌어내렸습니다. PG는 결제만 담당하는데, 결제와 관련 없는 상품 조회까지 안 되는 상황이 된 것입니다. 이것이 바로 Cascade Failure, 연쇄 장애입니다.
Circuit Breaker는 이 연쇄 장애를 끊어내는 역할을 합니다. PG 시스템이 장애 상태라면 즉시 실패를 반환하여, 스레드가 블로킹되는 것을 막고 다른 기능들이 정상 동작할 수 있도록 보호합니다.
4. Circuit Breaker의 세 가지 상태
전기 차단기는 ON과 OFF 두 가지 상태만 있습니다. 하지만 소프트웨어 Circuit Breaker는 세 가지 상태를 가집니다. CLOSED, OPEN, 그리고 HALF_OPEN입니다. 왜 중간 상태가 필요할까요?
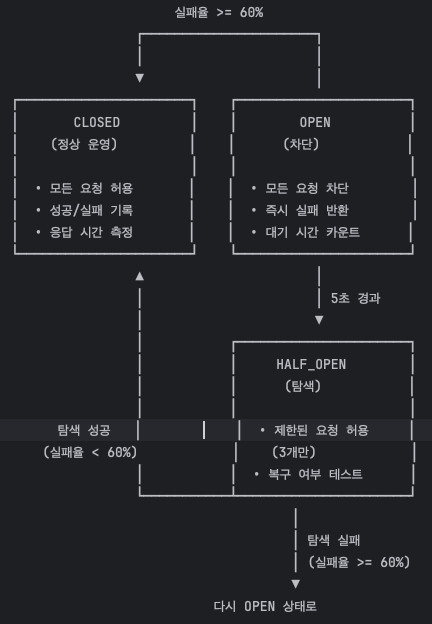
4.1 CLOSED: 정상 운영 상태
CLOSED 상태에서는 모든 요청이 외부 시스템으로 정상적으로 전달됩니다. 이 상태에서 Circuit Breaker는 조용히 결과를 관찰합니다. 성공인지 실패인지, 응답 시간은 얼마나 걸렸는지를 기록합니다.
최근 10번의 호출을 슬라이딩 윈도우로 관찰합니다.
slidingWindowType: COUNT_BASED
slidingWindowSize: 10
minimumNumberOfCalls: 5
최소 5번의 호출이 있어야 실패율 계산을 시작합니다. 서비스가 막 시작되었을 때 우연히 발생한 1~2번의 실패로 Circuit이 열리는 것을 방지하기 위함입니다.
4.2 OPEN: 차단 상태
OPEN 상태에서는 외부 시스템으로의 요청이 차단됩니다. 요청이 들어오면 실제로 PG 시스템을 호출하지 않고, Fallback 메서드가 실행됩니다.
@CircuitBreaker(name = "pgClient", fallbackMethod = "requestPaymentFallback")
override fun requestPayment(command: PgCommand.Request): PgInfo.Transaction {
log.info("PG 결제 요청 시작 - command: {}", command)
val request = PgDto.PgRequest(
orderId = command.orderId,
cardType = command.cardType,
cardNo = command.cardNo,
amount = command.amount,
callbackUrl = callbackUrl,
)
val response = pgClient.requestPayment(command.userId, request)
// ... 정상 처리
}
// OPEN 상태에서는 이 메서드가 실행됨
private fun requestPaymentFallback(
command: PgCommand.Request,
e: Exception,
): PgInfo.Transaction {
log.error(
"PG 결제 요청 Circuit Breaker 활성화 - userId: {}, orderId: {}",
command.userId, command.orderId, e
)
throw CoreException(
ErrorType.PG_SYSTEM_ERROR,
"결제 처리 중 오류가 발생했습니다. 잠시 후 다시 시도해주세요."
)
}
이 상태에서 사용자는 "결제 시스템이 일시적으로 불안정합니다"라는 메시지를 받게 됩니다. 1초를 기다린 후 실패하는 것이 아니라, 밀리초 단위로 즉시 응답을 받습니다.
4.3 HALF_OPEN: 탐색 상태
여기서 질문이 생깁니다. Circuit이 열린 후에는 어떻게 될까요? 영원히 열려 있으면 외부 시스템이 복구되어도 우리 시스템은 그것을 알 수 없습니다.
그래서 HALF_OPEN 상태가 필요합니다. 일정 시간이 지나면 Circuit은 자동으로 HALF_OPEN 상태로 전환되어 "외부 시스템이 복구되었는지" 탐색합니다.
waitDurationInOpenState: 5s # OPEN 상태 유지 시간 (5초 후 HALF_OPEN으로 전환)
automaticTransitionFromOpenToHalfOpenEnabled: true # OPEN → HALF_OPEN 자동 전환 활성화
permittedNumberOfCallsInHalfOpenState: 3 # HALF_OPEN 상태에서 3번의 테스트 호출 허용
OPEN 상태에서 5초가 지나면 자동으로 HALF_OPEN으로 전환됩니다. 이 상태에서는 3번의 "탐색 요청"만 허용됩니다. 나머지 요청들은 여전히 차단됩니다.
탐색 요청 3번 중 성공률이 임계값을 넘으면 Circuit은 다시 CLOSED 상태로 돌아갑니다. 외부 시스템이 복구되었다고 판단하는 것입니다. 반대로 탐색 요청들도 실패하면 다시 OPEN 상태로 돌아가고, 5초 후에 다시 탐색을 시도합니다.
이 세 가지 상태의 순환이 Circuit Breaker의 핵심입니다. 평상시에는 관찰하고(CLOSED), 문제가 생기면 차단하고(OPEN), 주기적으로 복구를 확인합니다(HALF_OPEN).
HALF_OPEN 상태 시나리오
[테스트 호출 1] → 성공 ✓
[테스트 호출 2] → 성공 ✓
[테스트 호출 3] → 성공 ✓
→ 모두 성공! CLOSED로 전환, 정상 운영 재개
또는
[테스트 호출 1] → 성공 ✓
[테스트 호출 2] → 실패 ✗
→ 실패 발생! 즉시 OPEN으로 전환, 5초 더 대기
5. 정답이 없는 임계값 설정의 딜레마
Circuit Breaker를 도입할 때 가장 어려운 부분은 "언제 열고, 언제 닫을 것인가"를 결정하는 것입니다. 이 값들에는 정답이 없습니다. 상황에 따라 트레이드오프가 달라지기 때문입니다.
5.1 실패율 임계값: 민감함 vs 둔감함
실패율 임계값을 낮게 설정하면(예: 30%) 작은 문제에도 빠르게 반응합니다. 하지만 일시적인 네트워크 지연이나 우연한 실패에도 Circuit이 열려버릴 수 있습니다. 정상적인 상황에서도 불필요하게 차단이 발생하는 것입니다.
반대로 임계값을 높게 설정하면(예: 80%) 안정적이지만, 실제 장애 상황에서 대응이 늦어집니다. 10번 중 7번이 실패해도 Circuit은 여전히 닫혀 있고, 그동안 리소스가 낭비됩니다.
만약 실패율 임계치를 50%로 설정하면, 정상 운영 중에도 회로가 열릴 수 있습니다. 40%의 정상 실패율에 네트워크 지연이 조금만 겹쳐도 50%를 넘기 때문입니다. 60%는 "명백히 뭔가 잘못됐다"고 판단할 수 있는 최소 임계치였습니다.
5.2 슬라이딩 윈도우 크기: 빠른 반응 vs 안정적 판단
윈도우 크기가 작으면(예: 5) 적은 샘플로 빠르게 판단합니다. 하지만 통계적 신뢰도가 낮습니다. 우연히 연속으로 3번 실패했다고 해서 시스템 전체가 장애인 것은 아닙니다.
윈도우 크기가 크면(예: 100) 통계적으로 신뢰할 수 있는 판단을 할 수 있습니다. 하지만 그만큼 많은 요청이 실패해야 Circuit이 열립니다. 장애 대응이 늦어지는 것입니다.
우리는 10으로 설정했습니다. 결제라는 중요한 기능에서 10번의 요청은 충분한 샘플이면서도, 너무 많은 실패를 허용하지 않는 균형점이라고 판단했습니다.
5.3 느린 호출 임계값: 타임아웃과의 관계
Circuit Breaker의 또 다른 강점은 "느린 호출"도 감지할 수 있다는 점입니다. 완전한 실패가 아니더라도, 응답이 비정상적으로 느려지는 것은 장애의 전조일 수 있습니다.
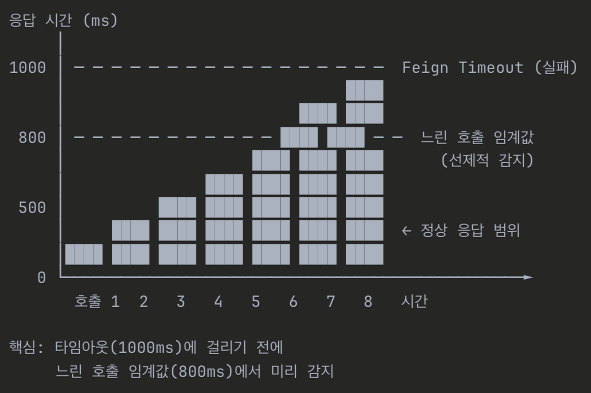
slowCallRateThreshold: 70 # 느린 호출 비율 70% 이상 시 circuit open
slowCallDurationThreshold: 800ms # 800ms 이상 걸리는 호출을 느린 호출로 판단 (정상 최대 500ms + 여유)
Feign 타임아웃은 1000ms로 설정되어 있고, 느린 호출 임계값은 800ms입니다. 타임아웃에 걸리지 않더라도 800ms 이상 걸리는 호출이 70%를 넘으면 Circuit이 열립니다.
이 설정은 "느려지기 시작하면 차단한다"는 선제적 대응을 가능하게 합니다. 완전히 다운되기 전에 미리 차단하여 전체 시스템을 보호하는 것입니다.
5.4 OPEN 상태 유지 시간: 복구 속도 vs 안정성
OPEN 상태를 얼마나 유지할 것인가도 중요한 결정입니다. 너무 짧으면(예: 1초) 외부 시스템이 복구되기도 전에 다시 요청을 보내게 됩니다. 복구 중인 시스템에 부하를 주어 복구를 방해할 수도 있습니다.
너무 길면(예: 1분) 외부 시스템이 복구되어도 오랫동안 서비스가 차단됩니다. 사용자 경험이 나빠집니다.
5초로 설정했습니다.
너무 짧으면(예: 1초) PG 시스템이 복구되기 전에 다시 요청을 보내게 됩니다. 복구 중인 시스템에 부하를 주면 복구가 더 늦어집니다. 너무 길면(예: 60초) 실제로는 3초만에 복구됐는데 57초 동안 불필요하게 서비스가 제한됩니다.
5초는 일반적인 서버 재시작/복구 시간입니다. 사용자 입장에서도 "잠시만 기다려주세요" 했을 때 참을 수 있는 시간이기도 합니다.
6. Retry와의 조합: 순서가 중요하다
Circuit Breaker만으로는 부족한 경우가 있습니다. 일시적인 네트워크 오류처럼 "다시 시도하면 성공할 수 있는" 실패도 있기 때문입니다. 그래서 Retry 패턴과 함께 사용합니다.

@Service
class PgService(
private val pgGateway: PgGateway,
) {
@Retry(name = "pgClient")
fun requestPayment(command: PgCommand.Request): String {
val transaction = pgGateway.requestPayment(command)
return transaction.transactionKey
}
}
여기서 중요한 것은 Retry와 Circuit Breaker의 적용 순서입니다. Service 레이어에서 Retry를, Infrastructure 레이어에서 Circuit Breaker를 적용했습니다. 요청 흐름으로 보면 Retry → Circuit Breaker → 실제 호출 순서입니다.
retry:
configs:
default:
maxAttempts: 2
waitDuration: 300ms
ignoreExceptions:
- io.github.resilience4j.circuitbreaker.CallNotPermittedException
핵심은 ignoreExceptions에 CallNotPermittedException이 포함되어 있다는 점입니다. Circuit이 열려서 차단된 경우에는 재시도하지 않습니다. 이미 외부 시스템이 장애 상태라고 판단했는데, 재시도해봤자 의미가 없기 때문입니다.
반대로 일시적인 네트워크 오류(TimeoutException, IOException)는 재시도합니다. 이런 오류는 다시 시도하면 성공할 가능성이 있습니다.
7. 예외 처리: 무엇을 실패로 볼 것인가
Circuit Breaker가 "실패"로 인식하는 예외를 신중하게 선택해야 합니다.
recordExceptions:
- org.springframework.web.client.HttpServerErrorException
- java.util.concurrent.TimeoutException
- java.io.IOException
ignoreExceptions:
- org.springframework.web.client.HttpClientErrorException
- com.loopers.support.error.CoreException
- java.lang.IllegalArgumentException
서버 에러(5xx), 타임아웃, IO 오류는 외부 시스템의 문제일 가능성이 높으므로 실패로 기록합니다. 반면 클라이언트 에러(4xx)나 비즈니스 예외는 무시합니다.
왜 클라이언트 에러를 무시할까요? 잘못된 카드 번호로 결제를 시도해서 400 에러가 발생했다고 가정해봅시다. 이것은 PG 시스템의 장애가 아니라 잘못된 입력입니다. 이런 에러까지 실패로 카운트하면, 사용자들이 잘못된 입력을 많이 하는 날에 Circuit이 열려버릴 수 있습니다.
8.결론 실패를 설계하라
분산 시스템에서 실패는 피할 수 없습니다. 중요한 것은 실패를 어떻게 다루느냐입니다. Circuit Breaker는 "실패할 것이 뻔한 요청을 미리 차단한다"는 단순한 아이디어지만, 이 아이디어가 전체 시스템의 안정성을 결정짓습니다.
전기 차단기가 집을 화재로부터 보호하듯, 소프트웨어 Circuit Breaker는 서비스를 연쇄 장애로부터 보호합니다. 차단기가 문제를 해결해주지는 않습니다. 하지만 문제가 더 커지는 것을 막아줍니다.
실패를 두려워하지 마세요. 대신 실패를 설계하세요. 어떤 실패를 허용할 것인지, 얼마나 허용할 것인지, 실패했을 때 어떻게 대응할 것인지를 미리 정해두세요. 그것이 견고한 시스템을 만드는 첫 번째 단계입니다.
루프백 3기 오픈
https://www.loopers.im/education
교육 과정 | Loop:Pak
Loop:Pak 부트캠프 교육 과정 상세 정보. NextNode Backend Edition을 포함한 전문 개발자 양성 커리큘럼과 현업 멘토링 프로그램을 만나보세요.
www.loopers.im
루퍼스 3기가 오픈되었습니다.
추천인 코드를 입력하면 할인가로 수강할 수 있습니다. 다만 결코 작은 금액은 아니기에, 신청 전 적지 않은 고민을 했는데요. AI 기술의 빠른 발전과 함께 연차가 쌓이면서, 스스로의 실력에 대한 의구심이 들던 시기였습니다.
며칠간 고민한 끝에 이번 기회를 마지막이라 생각하고 수강을 결정했습니다. 지금 돌이켜보면, 후회 없는 선택이었다고 자신 있게 말할 수 있습니다.
만약 저와 비슷한 고민을 하고 있거나, 루퍼스 과정에 대해 궁금한 점이 있다면 언제든지 편하게 연락 주셔도 좋습니다.
LinkedIn 또는 jikimee64@gmail.com으로 언제든 문의 부탁 드립니다. 감사합니다.
추천인 코드
TZFI0
'외부활동 > 루퍼스 2기' 카테고리의 다른 글
| [루퍼스/루프백 2기] Event-Driven Architecture 도입기: Command와 Event, 그리고 트랜잭션 경계 (0) | 2025.12.06 |
|---|---|
| [Loop:PAK] 6주차 WIL (0) | 2025.12.04 |
| [Loop:PAK] 5주차 WIL (0) | 2025.11.25 |
| [루퍼스/루프백 2기] 조회 성능을 높이는 방법을 설명할 수 있나요? (0) | 2025.11.22 |
| [Loop:PAK] 4주차 WIL (0) | 2025.11.17 |