TL;DR
- WHERE + ORDER BY 조합을 모두 포함하는 복합 인덱스로 정렬 비용 제거
- 브랜드별 최신순 조회: 18.6ms → 0.35ms (약 53배 개선)
- 실시간 COUNT() 대신 미리 계산된 좋아요 수 테이블로 집계 비용 절감
- 좋아요순 정렬 조회: 388ms → 0.185ms (약 2,097배 개선)
- Cache-Aside 패턴으로 읽기 중심 워크로드 최적화
- 트랜잭션 커밋 후 캐시 처리로 데이터 일관성 보장
서론
작년 면접에서 다음 질문을 받은 적이 있습니다.
💡 조회 성능을 높이는 방법을 설명해주세요.
그때는 인덱스, 쿼리 튜닝, 다중 쿼리 호출 개선을 언급했지만, 캐시 활용은 포함하지 못했습니다.
이번 글에서는 인덱스, 테이블 설계, 캐시 활용을 통한 조회 성능 개선을 다룹니다.
테스트 데이터 생성
조회 성능 테스트를 위해서는 실제 운영 환경과 유사한 데이터 분포가 필요합니다.
정확한 테스트를 위해 조회 쿼리의 WHERE 조건 컬럼 값을 분산되게 분포시키는 것이 중요합니다. 그 이유는 다음과 같습니다.
1. 옵티마이저의 정확한 실행 계획 수립
- MySQL 옵티마이저는 통계 정보(히스토그램, 카디널리티)를 기반으로 실행 계획을 결정합니다
- 데이터가 편향되어 있으면 옵티마이저가 실제 운영 환경과 다른 판단을 내릴 수 있습니다
2. 실제 디스크 I/O 성능 측정
- 특정 값에 데이터가 몰려있으면 버퍼 풀 캐시나 OS 페이지 캐시에 해당 데이터가 지속적으로 유지됩니다
- 이 경우 실제 디스크 I/O 성능을 측정할 수 없습니다
데이터 적재 전략
총 10만 개의 상품, 100개의 브랜드, 50만 개의 좋아요 데이터를 생성했습니다.
실제 이커머스 환경을 고려하여 파레토 법칙(80:20 법칙) 을 적용했습니다:
가격 분포
- 70%: 1만원~5만원 (저가)
- 20%: 5만원~20만원 (중가)
- 10%: 20만원~100만원 (고가)
브랜드 분포
- 80%: 상위 20개 브랜드에 집중
- 20%: 나머지 80개 브랜드에 분산
이를 JUnit 테스트 코드로 구현하여 데이터를 적재했습니다.
@SpringBootTest
@ActiveProfiles("local")
@Disabled("상품 데이터 더미 생성")
class ProductDummyGeneratorTest {
private val log = LoggerFactory.getLogger(javaClass)
@Autowired
private lateinit var brandJpaRepository: BrandJpaRepository
@Autowired
private lateinit var productJpaRepository: ProductJpaRepository
@Autowired
private lateinit var productLikeJpaRepository: ProductLikeJpaRepository
@Autowired
private lateinit var productLikeCountJpaRepository: ProductLikeCountJpaRepository
@Test
fun `브랜드 - 상품 데이터 생성`() {
// 1. 브랜드 생성 (100개)
log.info("브랜드 생성 중...")
val brands = createBrands(100)
brandJpaRepository.saveAll(brands)
val brandIds = brands.map { it.id }
log.info("브랜드 {}개 생성 완료", brands.size)
// 2. 상품 생성 (10만개) - 배치 처리
log.info("상품 생성 중...")
val batchSize = 1000
var totalCreated = 0
repeat(100) { batchIndex ->
val products = createProducts(
count = batchSize,
brandIds = brandIds,
startIndex = batchIndex * batchSize,
)
productJpaRepository.saveAll(products)
totalCreated += products.size
if ((batchIndex + 1) % 10 == 0) {
log.info("진행률: {}/100,000", totalCreated)
}
}
log.info("상품 {}개 생성 완료", totalCreated)
}
@Test
fun `상품 좋아요 데이터 생성`() {
// 1. 상품 ID 조회
val productIds = productJpaRepository.findAll().map { it.id }
require(productIds.isNotEmpty()) { "상품 데이터가 없습니다. generateProductDummyData()를 먼저 실행하세요." }
log.info("상품 {}개 조회 완료", productIds.size)
// 2. 좋아요 생성 (50만개) - 배치 처리
log.info("좋아요 생성 중...")
val batchSize = 5000
var totalCreated = 0
val createdPairs = mutableSetOf<Pair<Long, Long>>() // 중복 방지
// 가상의 사용자 ID 풀 (1~1000번)
val userIdPool = (1L..1000L).toList()
repeat(100) { batchIndex ->
val likes = mutableListOf<ProductLike>()
while (likes.size < batchSize) {
val userId = userIdPool.random()
val productId = productIds.random()
val pair = Pair(userId, productId)
if (!createdPairs.contains(pair)) {
likes.add(ProductLike.create(productId, userId))
createdPairs.add(pair)
}
}
productLikeJpaRepository.saveAll(likes)
totalCreated += likes.size
if ((batchIndex + 1) % 10 == 0) {
log.info("진행률: {}/500,000", totalCreated)
}
}
log.info("좋아요 {}개 생성 완료", totalCreated)
}
@Test
fun `상품 좋아요 카운트 데이터 생성`() {
// 1. 전체 상품 ID 조회
val productIds = productJpaRepository.findAll().map { it.id }
require(productIds.isNotEmpty()) { "상품 데이터가 없습니다." }
log.info("상품 {}개 조회 완료", productIds.size)
// 2. ProductLike 데이터 기반으로 집계
log.info("좋아요 집계 중...")
val likeCountMap = productLikeJpaRepository.findAll()
.groupBy { it.productId }
.mapValues { it.value.size.toLong() }
log.info("집계 완료: {}개 상품에 좋아요 존재", likeCountMap.size)
// 3. ProductLikeCount 생성 (배치 처리)
log.info("ProductLikeCount 생성 중...")
val batchSize = 1000
var totalCreated = 0
productIds.chunked(batchSize).forEachIndexed { batchIndex, productIdBatch ->
val productLikeCounts = productIdBatch.map { productId ->
ProductLikeCount.create(
productId = productId,
likeCount = likeCountMap[productId] ?: 0L,
)
}
productLikeCountJpaRepository.saveAll(productLikeCounts)
totalCreated += productLikeCounts.size
if ((batchIndex + 1) % 10 == 0) {
log.info("진행률: {}/{}", totalCreated, productIds.size)
}
}
log.info("ProductLikeCount {}개 생성 완료", totalCreated)
// 4. 검증
val totalLikes = likeCountMap.values.sum()
val savedTotalLikes = productLikeCountJpaRepository.findAll().sumOf { it.likeCount }
log.info("검증 - 원본 좋아요 수: {}, 저장된 좋아요 수: {}", totalLikes, savedTotalLikes)
require(totalLikes == savedTotalLikes) { "좋아요 수 불일치!" }
}
private fun createBrands(count: Int): List<Brand> {
return (1..count).map { index ->
Brand.create(name = "브랜드_$index")
}
}
private fun createProducts(count: Int, brandIds: List<Long>, startIndex: Int): List<Product> {
val categories = listOf("의류", "신발", "가방", "액세서리", "전자기기", "도서", "식품", "화장품")
val adjectives = listOf("프리미엄", "베스트", "신상", "인기", "한정판", "특가", "추천", "고급")
return (1..count).map { index ->
val globalIndex = startIndex + index
val category = categories.random()
val adjective = adjectives.random()
// 가격 분포: 파레토 법칙 적용 (대부분 저가, 일부 고가)
val price = when (Random.nextInt(100)) {
in 0..69 -> Random.nextLong(10_000, 50_000) // 70% - 저가
in 70..89 -> Random.nextLong(50_000, 200_000) // 20% - 중가
else -> Random.nextLong(200_000, 1_000_000) // 10% - 고가
}
// 브랜드 분포: 상위 20% 브랜드에 80% 상품 집중
val brandId = if (Random.nextInt(100) < 80) {
// 상위 20개 브랜드 중 선택
brandIds.take(20).random()
} else {
// 나머지 브랜드 중 선택
brandIds.drop(20).random()
}
Product.create(
name = "${adjective}_${category}_상품_$globalIndex",
price = price,
brandId = brandId,
)
}
}
}브랜드별 최신순 조회 개선
상품 리스트 조회 쿼리 성능을 개선해야 했습니다.
도메인 모델
@Table(
name = "product",
indexes = [
Index(name = "idx_product_brand_id", columnList = "ref_brand_id")
],
)
class Product(
@Column(nullable = false, unique = true, columnDefinition = "varchar(100)")
val name: String,
@Column(nullable = false)
val price: Long,
@Column(name = "ref_brand_id", nullable = false)
val brandId: Long,
)
개선 전: 인덱스 미적용
쿼리
SELECT p.*
FROM product p
WHERE p.ref_brand_id = 1
ORDER BY p.created_at DESC
LIMIT 20;
```
**실행 계획 (EXPLAIN ANALYZE)**
```
-> Limit: 20 row(s) (cost=815 rows=20) (actual time=18.6..18.6 rows=20 loops=1)
-> Sort: p.created_at DESC, limit input to 20 row(s) per chunk (cost=815 rows=4065) (actual time=18.6..18.6 rows=20 loops=1)
-> Index lookup on p using idx_product_brand_id (ref_brand_id=1) (cost=815 rows=4065) (actual time=1.42..15.8 rows=4065 loops=1)
실행 시간: 18.6ms
문제점
- 4,065건을 created_at 기준으로 메모리에서 정렬 (filesort 발생)
- WHERE 조건만 인덱스를 사용하고, ORDER BY는 추가 정렬 필요
동작 방식
- idx_product_brand_id로 ref_brand_id=1인 데이터 스캔 → 4,065건 읽기
- 4,065건을 created_at 기준으로 메모리에서 정렬 → O(N log N) 비용
- 상위 20건 추출
개선 후: 복합 인덱스 적용
WHERE 조건과 ORDER BY를 모두 커버하는 복합 인덱스를 생성했습니다.
인덱스 생성
CREATE INDEX idx_product_brand_id_created_at
ON product (ref_brand_id, created_at DESC);
```
**실행 계획**
```
-> Limit: 20 row(s) (cost=815 rows=20) (actual time=0.348..0.355 rows=20 loops=1)
-> Index lookup on p using idx_product_brand_id_created_at (ref_brand_id=1) (cost=815 rows=4065) (actual time=0.346..0.352 rows=20 loops=1)
실행 시간: 0.348ms
동작 방식
- idx_product_brand_id_created_at로 ref_brand_id=1 영역으로 이동 (B-Tree 탐색)
- 이미 created_at DESC로 정렬된 상태이므로 순차적으로 20건만 읽고 즉시 종료
성능 비교
| 항목 | 개선 전 | 개선 후 |
| 읽은 건수 | 4,065건 | 20건 |
| 정렬 방식 | Using filesort | 인덱스 스캔 |
| 총 시간 | 18.6ms | 0.35ms |
| 시간 복잡도 | O(N Log N) | O(1) |
개선율: 약 53배
좋아요순 정렬 조회 개선
개선 전: 실시간 COUNT() 집계
쿼리
SELECT p.*
FROM product p
LEFT JOIN product_like pl ON p.id = pl.ref_product_id
GROUP BY p.id
ORDER BY COUNT(pl.id) DESC
LIMIT 20;
```
**실행 계획**
```
-> Limit: 20 row(s) (actual time=388..388 rows=20 loops=1)
-> Sort: `count(pl.id)` DESC, limit input to 20 row(s) per chunk (actual time=388..388 rows=20 loops=1)
-> Stream results (cost=129349 rows=99607) (actual time=0.887..375 rows=100000 loops=1)
-> Group aggregate: count(pl.id) (cost=129349 rows=99607) (actual time=0.772..314 rows=100000 loops=1)
-> Nested loop left join (cost=82265 rows=470849) (actual time=0.759..278 rows=500696 loops=1)
-> Index scan on p using PRIMARY (cost=10097 rows=99607) (actual time=0.534..31.3 rows=100000 loops=1)
-> Covering index lookup on pl using idx_product_like_product_id (ref_product_id=p.id) (cost=0.252 rows=4.73) (actual time=0.0016..0.00215 rows=5 loops=100000)
실행 시간: 388ms
주요 문제점
1. 매번 전체 테이블 스캔 후 COUNT 계산
- COUNT(pl.id)를 계산하기 위해 매번 product_like 테이블 전체를 조회해야 합니다
- 상품이 많고 좋아요가 많을수록 성능이 급격히 저하됩니다
- GROUP BY와 COUNT 연산은 매우 비용이 큽니다
2. 인덱스 활용 불가
- ORDER BY COUNT(pl.id) DESC는 집계 함수 결과로 정렬하므로 인덱스를 활용할 수 없습니다
- 임시 테이블(temporary table)과 파일 정렬(filesort)이 발생합니다
3. 실시간 계산의 비효율성
- 좋아요 수는 변경 빈도가 낮지만, 조회 빈도는 매우 높은 데이터입니다
- 매번 실시간으로 계산하는 것은 비효율적입니다
개선 후: 좋아요 수 사전 계산 테이블
좋아요 수를 미리 계산하여 보관하는 ProductLikeCount 테이블을 추가했습니다.
도메인 모델
@Table(name = "product_like_count")
class ProductLikeCount(
@Column(name = "ref_product_id", nullable = false, unique = true)
val productId: Long,
@Column(name = "like_count", nullable = false)
var likeCount: Long = 0,
)
인덱스 생성
CREATE INDEX idx_product_like_count_count
ON product_like_count (like_count DESC);
수정된 쿼리
SELECT p.*
FROM product_like_count plc
JOIN product p ON p.id = plc.ref_product_id
ORDER BY plc.like_count DESC
LIMIT 20;
```
**실행 계획**
```
-> Limit: 20 row(s) (cost=24992 rows=20) (actual time=0.185..0.254 rows=20 loops=1)
-> Nested loop inner join (cost=24992 rows=20) (actual time=0.184..0.251 rows=20 loops=1)
-> Index scan on plc using idx_product_like_count_count (cost=0.0181 rows=20) (actual time=0.161..0.165 rows=20 loops=1)
-> Single-row index lookup on p using PRIMARY (id=plc.ref_product_id) (cost=0.25 rows=1) (actual time=0.00391..0.00394 rows=1 loops=20)
실행 시간: 0.185ms
쿼리 최적화 포인트
1. FROM 절 순서
- product_like_count를 FROM 절에 먼저 배치했습니다
- 정렬된 20건을 먼저 찾은 다음, 그 20건에 대해서만 product를 조인합니다
- 데이터 모수를 대폭 줄일 수 있습니다
만약 product를 FROM 절에 두면 10만 건을 모두 읽은 후 조인하여 10만 건을 모두 정렬해야 합니다
2. Nested Loop Join의 효율성
- Outer loop (driving table: product_like_count): 20건만 스캔
- Inner loop (driven table: product): PK로 20건만 조회
옵티마이저가 자동으로 최적화할 수도 있지만, 잘못 판단할 가능성을 배제하기 위해 명시적으로 배치했습니다.
실시간 동기화 구현
좋아요 등록/취소 시 ProductLikeCount를 실시간으로 업데이트합니다.
@Service
class ProductLikeService(
private val productLikeRepository: ProductLikeRepository,
) {
@Transactional
fun like(product: Product, user: User) {
if (productLikeRepository.existsBy(product.id, user.id)) {
return
}
val result = productLikeRepository.increaseCount(product.id)
if (result == 0) {
productLikeRepository.saveCount(ProductLikeCount.create(product.id, 1L))
}
productLikeRepository.save(ProductLike.create(product.id, user.id))
}
@Transactional
fun unlike(product: Product, user: User) {
productLikeRepository.findBy(product.id, user.id) ?: return
productLikeRepository.decreaseCount(product.id)
return productLikeRepository.deleteBy(product.id, user.id)
}
}
성능 비교
| 항목 | 개선 전 | 개선 후 |
| 처리 건수 | 최소 50만 건 이상 (조인 결과) | 20건 |
| GROUP BY | 314ms | 없음 |
| 정렬 방식 | Using filesort | 인덱스 스캔 |
| 총 시간 | 388ms | 0.185ms |
| 확장성 | O(N×M) | O(1) |
개선율: 약 2,097배
인덱스 & 테이블 설계 결론
조회 성능 개선은 인덱스 설계와 테이블 구조 최적화의 조합으로 달성할 수 있습니다.
핵심 원칙
- WHERE + ORDER BY를 함께 고려한 복합 인덱스 설계
- 정렬 비용을 제거하고 필요한 건수만 읽기
- 읽기 전용 데이터의 사전 계산
- 집계 비용이 큰 데이터는 미리 계산하여 저장
- 쿼리 실행 계획 분석
- EXPLAIN ANALYZE로 병목 지점을 정확히 파악
이번 개선으로 브랜드별 조회는 53배, 좋아요순 정렬은 2,097배 빨라졌습니다.
실제 운영 환경에서는 여기에 Redis 캐시를 추가로 적용하여 더욱 빠른 응답 속도를 달성할 수 있습니다.
캐시
인덱스와 테이블 구조 개선으로 조회 성능을 대폭 향상시켰지만, 여전히 모든 요청이 DB를 거칩니다.
상품 정보는 변경 빈도가 낮지만 조회 빈도가 매우 높은 전형적인 읽기 중심 데이터입니다. 이런 경우 캐시를 적용하면 다음과 같은 효과를 얻을 수 있습니다:
- DB 부하 감소
- 응답 속도 향상
- 인프라 비용 절감
이번 글에서는 Redis를 활용한 캐시 전략과 설계 의사결정 과정을 다룹니다.
캐시 적용 대상
1. 상품 리스트 (GET /api/v1/products)
캐시 키 전략
product:{version}:list:{brandId}:{sort}:{page}
설계 결정
- 브랜드 필터, 정렬 기준, 페이지 정보를 조합하여 캐시 키를 생성합니다.
- 최대 4페이지까지만 캐시: 5페이지 이상은 조회 빈도가 급격히 낮아 메모리 효율성이 저하됩니다.
- TTL: 30분: 상품 정보는 자주 변경되지 않습니다.
2. 상품 상세 (GET /api/v1/products/{productId})
캐시 키 전략
product:{version}:detail:{productId}:{userId}
설계 결정
- 사용자별로 좋아요 여부가 다르므로 userId를 포함합니다.
- 비로그인 사용자는 `anonymous`로 통일합니다.
- TTL: 30분: 좋아요 수가 30분간 다소 부정확해도 UX에 큰 영향이 없습니다.
3. 내가 좋아요 한 상품 (GET /api/v1/like/products)
캐시 키 전략
product:{version}:liked:{userId}:{page}
설계 결정
- TTL 3분: 좋아요는 변경 빈도가 높고 즉각 반영이 중요합니다.
- 최대 4페이지까지만 캐시: 동일한 메모리 효율성 전략을 채택합니다.
- 캐시 삭제 실패 시에도 3분 후 자연 만료로 일관성을 보호합니다.
캐시 패턴 선택: Cache-Aside
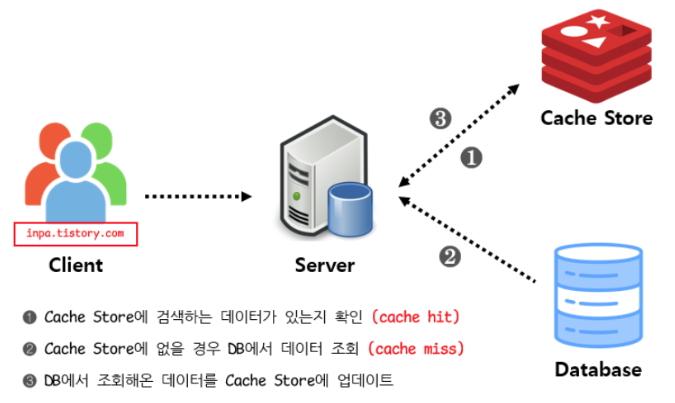
선택 이유
1. 읽기 위주의 워크로드
- 상품 조회는 매우 빈번하지만 상품 수정은 드뭄니다.
- 캐시 미스 시에만 DB 부하가 발생합니다.
- 대부분의 요청이 캐시에서 처리됩니다.
2. 데이터 일관성 관리 용이
- 애플리케이션이 캐시 저장/삭제 시점을 완전히 제어 합니다.
- 좋아요 변경 시 관련 캐시만 선택적으로 삭제 가능 합니다.
- DB와 캐시 간 불일치가 최소화 됩니다.
3. 장애 격리
- Redis 장애 시에도 서비스 중단이 없습니다.
- 캐시 조회 실패 시 자동으로 DB로 폴백합니다.
- 시스템 안정성이 향상됩니다.
다른 패턴과의 비교
| 패턴 | 장점 | 단점 | 적합성 |
| Cache-Aside | 애플리케이션이 캐시 제어, 장애 격리 | 캐시 미스 시 지연 | 채택 ✅ |
| Write-Through | 항상 최신 데이터 보장 | 모든 쓰기가 캐시 거침 (성능 저하) | ❌ 쓰기가 적어 과도함 |
| Write-Behind | 쓰기 성능 우수 | 데이터 유실 위험 | ❌ 데이터 정합성 중요 |
| Refresh-Ahead | 캐시 미스 최소화 | 복잡한 구현, 불필요한 갱신 | ❌ 단순한 워크로드에 과도함 |
트랜잭션과 캐시의 일관성
문제 상황
// ❌ 잘못된 방식: 트랜잭션 커밋 전 캐시 삭제
@Transactional
fun like(productId: Long, userId: String) {
productLikeService.like(product, user) // DB에 저장 (트랜잭션 내)
productCache.evictProductDetail(productId) // 캐시 삭제
throw RuntimeException() // 롤백 발생!
}
결과: DB는 롤백되었지만 캐시는 이미 삭제됨 → 데이터 불일치
발생 가능한 문제
1. 트랜잭션 롤백 시 캐시 불일치
- DB는 롤백되었지만 캐시는 이미 변경 되었습니다.
- 이후 조회 시 존재하지 않는 데이터가 반환될 수 있습니다.
2. 커밋 실패 시 캐시 오염
- 캐시는 저장되었지만 DB 커밋에 실패 합니다.
- 캐시에는 존재하지만 DB에는 없는 데이터가 있을 수 있습니다.
해결: 커밋 후 캐시 처리
@Transactional
fun like(productId: Long, userId: String) {
productLikeService.like(product, user)
// 트랜잭션 커밋 후 실행
TransactionUtils.executeAfterCommit {
productCache.evictProductDetail(productId)
productCache.evictLikedProductList(userId)
}
}
구현
object TransactionUtils {
fun executeAfterCommit(action: () -> Unit) {
if (TransactionSynchronizationManager.isActualTransactionActive()) {
TransactionSynchronizationManager.registerSynchronization(
object : TransactionSynchronization {
override fun afterCommit() {
try {
action()
} catch (e: Exception) {
logger.error("캐시 처리 실패", e)
// 캐시 실패는 로깅만 하고 서비스는 계속 동작
}
}
}
)
} else {
action()
}
}
}장점
1. 데이터 일관성 보장
- DB 커밋이 성공한 경우에만 캐시 변경
- 롤백 시 캐시도 변경되지 않음
2. 동시성 안전
- 커밋 시점 이후에 캐시 삭제/저장
- 다른 트랜잭션이 오래된 데이터를 캐시에 저장할 위험 감소
3. 장애 격리
- 캐시 오류가 트랜잭션 성공에 영향을 주지 않음
- 캐시 실패는 로깅만 하고 서비스는 계속 동작
캐시 결론
캐시는 단순히 응답 속도를 높이는 것을 넘어, 시스템 전체의 안정성을 향상시키는 핵심 요소입니다.
핵심 설계 원칙
1. 워크로드에 맞는 패턴 선택
- 읽기 중심: Cache-Aside
- 애플리케이션이 캐시를 완전히 제어
2. 데이터 일관성 우선
- 트랜잭션 커밋 후 캐시 처리
- 성능보다 정합성이 중요
3. 무중단 배포 고려
- 캐시 키 버전 관리
- 기존 캐시와 충돌 방지
4. 적절한 TTL과 범위
- 데이터 특성에 맞는 TTL 설정
- 메모리 효율성을 고려한 캐시 범위
기대 효과
- DB 부하 감소: 대부분의 조회 요청이 캐시에서 처리
- 응답 속도 향상: 네트워크 + DB 쿼리 시간 절약
- 확장성 향상: DB가 아닌 Redis로 트래픽 분산
인덱스 최적화와 캐시 적용을 통해 조회 성능을 최대한 끌어올렸습니다. 다음 단계는 모니터링을 통해 실제 캐시 히트율을 측정하고, 필요시 TTL과 캐시 범위를 조정하는 것입니다.
루프백 3기 오픈
https://www.loopers.im/education
교육 과정 | Loop:Pak
Loop:Pak 부트캠프 교육 과정 상세 정보. NextNode Backend Edition을 포함한 전문 개발자 양성 커리큘럼과 현업 멘토링 프로그램을 만나보세요.
www.loopers.im
루퍼스 3기가 오픈되었습니다.
추천인 코드를 입력하면 할인가로 수강할 수 있습니다. 다만 결코 작은 금액은 아니기에, 신청 전 적지 않은 고민을 했는데요. AI 기술의 빠른 발전과 함께 연차가 쌓이면서, 스스로의 실력에 대한 의구심이 들던 시기였습니다.
며칠간 고민한 끝에 이번 기회를 마지막이라 생각하고 수강을 결정했습니다. 지금 돌이켜보면, 후회 없는 선택이었다고 자신 있게 말할 수 있습니다.
만약 저와 비슷한 고민을 하고 있거나, 루퍼스 과정에 대해 궁금한 점이 있다면 언제든지 편하게 연락 주셔도 좋습니다.
LinkedIn 또는 jikimee64@gmail.com으로 언제든 문의 부탁 드립니다. 감사합니다.
추천인 코드
TZFI0
'외부활동 > 루퍼스 2기' 카테고리의 다른 글
| [루퍼스/루프백 2기] 실패를 실패로 끝내지 않는 법: Circuit Breaker의 철학 (0) | 2025.12.04 |
|---|---|
| [Loop:PAK] 5주차 WIL (0) | 2025.11.25 |
| [Loop:PAK] 4주차 WIL (0) | 2025.11.17 |
| [루퍼스/루프백 2기] 이커머스 동시성 제어 및 낙관적 락과 비관적 락 선택 기준 (0) | 2025.11.17 |
| [Loop:PAK] 3주차 WIL (0) | 2025.11.14 |