TL;DR
- Redis ZSET으로 일간 실시간 랭킹을 구현
- 조회/좋아요/주문 이벤트를 가중치로 합산해 점수를 누적
- 윈도우 교체 시 생기는 콜드 스타트는 캐리오버 또는 “전날 10% + 오늘 90%” 가중합으로 완화
- 텀블링 윈도우는 쉽고 명확하지만 콜드 스타트가 생기며, 슬라이딩 윈도우는 자연스럽지만 구현 난이도가 높음.
들어가며
이커머스에서 랭킹은 “유저가 어떤 상품을 발견하느냐”를 바꾸는 중요한 영역입니다.
문제는 실시간성과 성능을 동시에 만족시키기 어렵다는 점이다. DB의 ORDER BY만으로는 높은 트래픽을 감당하기 어렵고, 윈도우가 바뀌는 순간 랭킹이 비는 콜드 스타트 문제도 생깁니다.
이번 미션에서는 Redis ZSET을 기반으로 1일 단위 실시간 랭킹을 구현하고, 이벤트 가중치 합산과 콜드 스타트 완화 방식(캐리오버/가중합)을 적용해본 과정을 정리합니다.
sorted set(zset)
sorted set과 zset은 동일한 의미인데요. 이하 글에서는 용어 통일상 zset이라 표기 하겠습니다.
zset이란
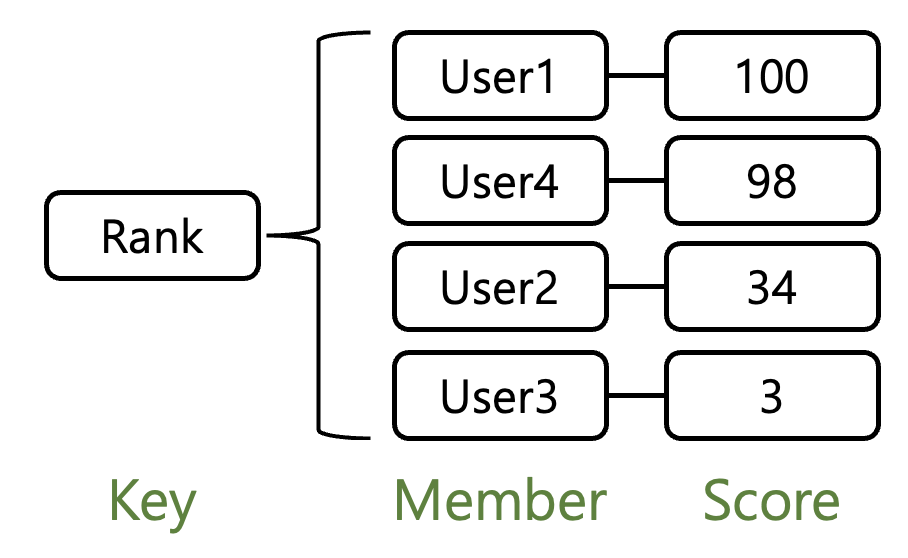
스코어(score) 값에 따라 정렬되는 고유한 문자열의 집합입니다. 중복을 허용하지 않으면서도 각 아이템이 스코어라는 숫자 데이터에 연결되어 있어, 이를 기준으로 자동 정렬된다는 점이 가장 큰 특징입니다. 즉, 단순한 key-value가 아니라 정렬된 집합 구조입니다.
key는 하나의 zet에 부여되는 식별자 입니다. 하나의 zset에 member는 unique하고, memer 값을 통해 score에 접근할 수 있습니다.
zset 주요 특징 및 장점
아이템이 저장될 때부터 스코어 값으로 정렬되어 저장되므로, 데이터를 읽어올 때 매번 정렬할 필요가 없습니다. 스코어가 같을 경우에는 데이터의 사전 순으로 정렬됩니다.
인덱스를 이용해 데이터에 접근할 때, List는 O(N)의 시간이 걸리는 반면 Sorted Set은 O(logN)으로 처리되어 데이터 양이 많아질수록 훨씬 효율적입니다.
💡 큰 반환 값(예: 수만 개 이상)을 사용하여 ZRANGE 명령을 실행할 때는 주의를 기울여야 합니다.
이 명령의 시간 복잡도는 O(log(n) + m)이며, 여기서 m은 반환된 결과 수입니다.
유연한 조회
인덱스 기반의 조회뿐만 아니라 스코어 범위(BYSCORE), 사전 순 범위(BYLEX) 등 다양한 조건으로 데이터를 검색할 수 있습니다.
주요 활용 사례
실시간 리더보드
사용자의 점수를 스코어로 설정하면 실시간으로 순위가 계산되는 리더보드를 쉽게 구현할 수 있습니다. 점수가 업데이트되면 순위도 자동으
로 재정렬됩니다.
최근 검색 기록
사용자가 검색한 시간을 스코어로 지정하면 중복을 제거하면서도 시간 순으로 정렬된 최근 검색 내역을 효율적으로 관리할 수 있습니다.
태그 및 카운팅
태그, 카테고리, 키워드에 가중치(빈도, 점수, 중요도) 를 부여하여 인기 순, 빈도 순으로 정렬·조회할 때 사용됩니다
위치 기반 서비스(Geospatial)
레디스의 위치 데이터(경도, 위도) 저장 구조는 내부적으로 Sorted Set을 사용하여 관리됩니다.
zset 대표적인 커맨드
// 실행
ZADD leaderboard 100 user:1
ZADD leaderboard 200 user:2
ZADD leaderboard 150 user:3
// 결과
(integer) 1- leaderboard : ZSET key
- user:1 : member
- 100 : score
이미 존재하는 member에 다시 추가하면
ZADD leaderboard 180 user:1user:1의 score가 100 → 180 으로 업데이트됩니다 (누적이 아니고 덮어쓰기 입니다)
오름차순
// 실행 (오름차순)
ZRANGE leaderboard 0 -1 WITHSCORES
1) "user:3"
2) "150"
3) "user:1"
4) "180"
5) "user:2"
6) "200"
// 실행 (내림차순)
ZREVRANGE leaderboard 0 -1 WITHSCORES
1) "user:2"
2) "200"
3) "user:1"
4) "180"
5) "user:3"
6) "150"// 실행
ZINCRBY leaderboard 20 user:3
// 결과
"170"- user:3의 score: 150 → 170
- 음수도 가능
ZINCRBY leaderboard -30 user:2- 200 -> 170
// 실행
ZADD week1 100 user:1 200 user:2
ZADD week2 50 user:1 300 user:3
// 실행
ZUNIONSTORE total_rank 2 week1 week2
// 결과
(integer) 3
// 조회
ZRANGE total_rank 0 -1 WITHSCORES
// 결과
1) "user:1"
2) "150"
3) "user:2"
4) "200"
5) "user:3"
6) "300"
// 실행
ZREMRANGEBYRANK search_history 0 99
zset 내부 구현
zset을 사용하여 실시간 랭킹을 구현하면 빠른 이유가 무엇일까요? 내부 구현 원리를 간단하게 살펴 보려고 합니다.
skip list
Sorted Set의 정렬 및 랭킹 기능을 담당하는 핵심 구조는 스킵 리스트입니다.
skip list 특징은 다음과 같습니다.
- 연결 리스트가 계층을 구성함
- 각 연결 리스트는 값을 순서대로 가짐
- 0 레벨 : 전체 값을 가짐
- 상위 레벨 : 하위 노드에서 일부 노드만 포함
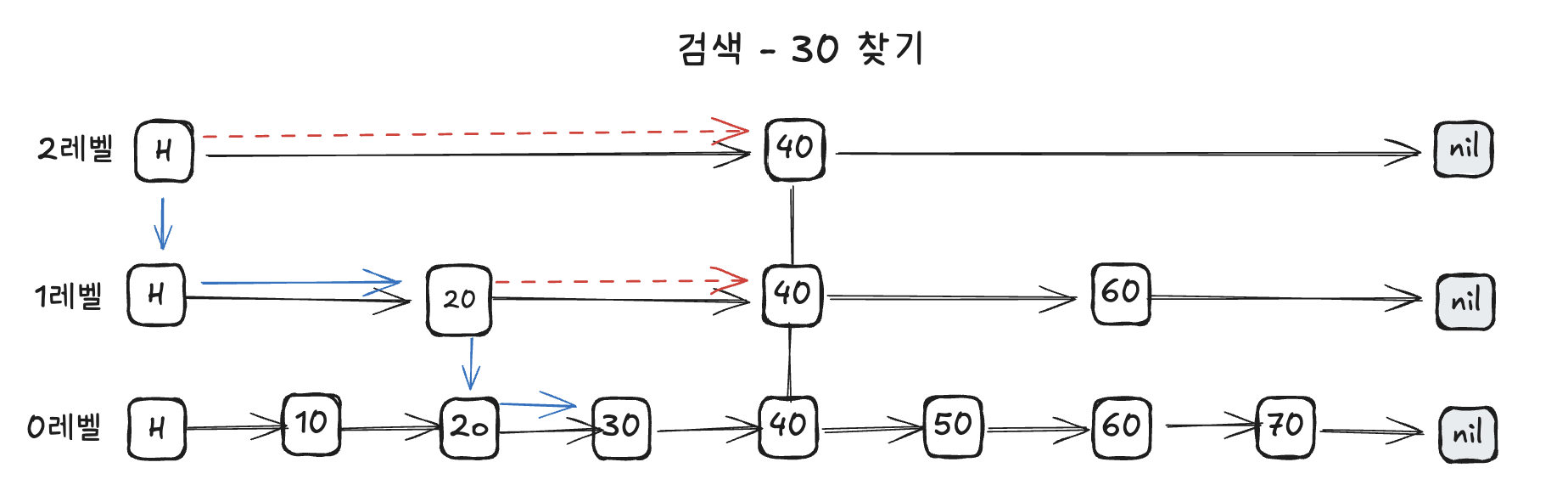
10부터 70까지 score가 있을때 30을 찾는다 가정 해봅시다.
계층적 구조
연결 리스트가 여러 층(Level 0, 1, 2...)으로 쌓여 있는 형태입니다. 최하단인 0레벨은 전체 데이터를 모두 가지고 있으며, 상위 레벨로 갈수록 더 적은 수의 노드를 가집니다.
효율적인 탐색
최상위 레벨부터 시작하여 타겟보다 큰 값을 만나면 아래 레벨로 내려가며 찾는 방식을 취합니다. 이 덕분에 일반 연결 리스트의 O(N) 성능을 O(logN)까지 끌어올려 트리 구조와 유사한 효율을 보입니다.
데이터 처리
데이터의 삽입, 삭제 역시 탐색과 동일한 방식으로 위치를 찾아 수행됩니다.
스팬
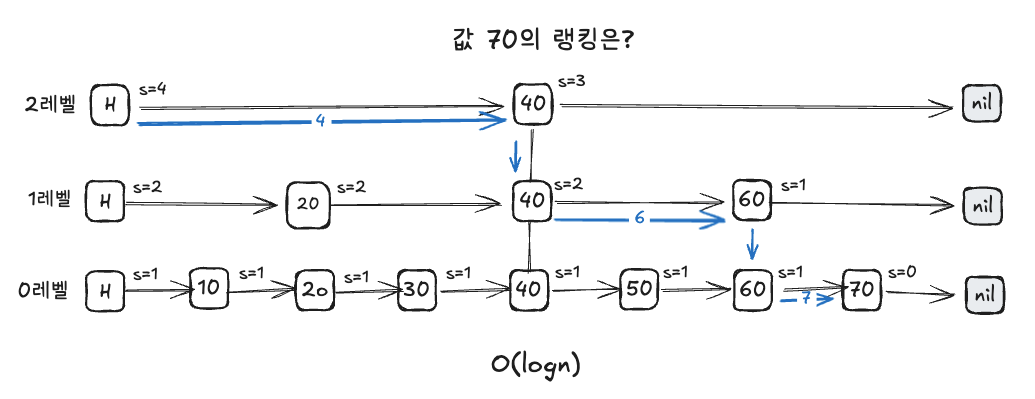
단순히 값만 찾는 것이 아니라 특정 데이터가 '몇 등'인지 빠르게 계산하기 위해 스팬(Span)이라는 정보를 추가로 관리합니다.
스팬의 정의
각 노드 간의 간격(거리)을 의미합니다. 예를 들어, 0레벨 노드 간의 간격은 1이지만, 건너뛰는 노드가 있는 상위 레벨에서는 간격이 2나 4 등으로 커집니다.
순위 산출 방식
특정 값을 찾아가는 과정에서 거쳐온 노드들의 스팬 값을 모두 합산하면 해당 데이터의 정확한 순위(랭킹)를 바로 알 수 있습니다. 이 과정 역시 O(logN)의 성능으로 매우 빠르게 처리됩니다.
hash table
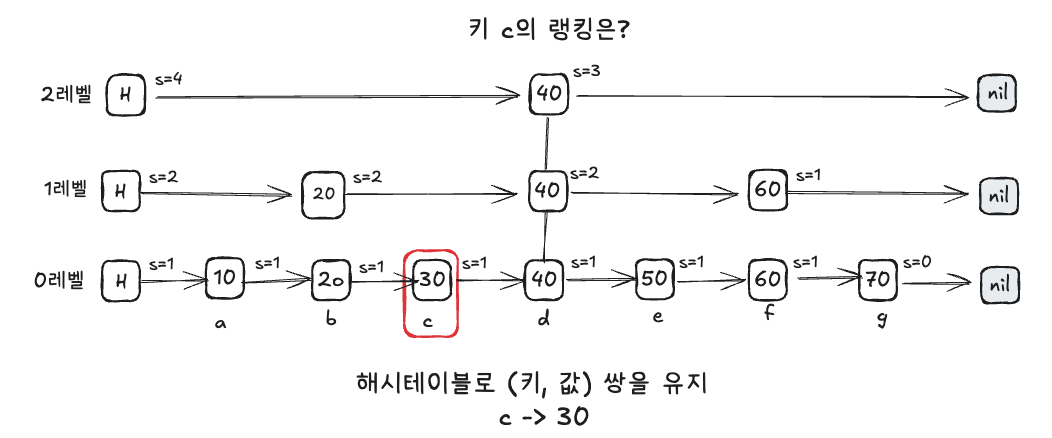
레디스는 특정 키(Key)에 대한 랭킹을 더 빠르게 찾기 위해 해시 테이블을 병행 사용합니다.
동작 원리
해시 테이블은 '키'와 '값(스코어)'의 쌍을 관리합니다. 사용자가 특정 키의 순위를 물어보면, 먼저 해시 테이블에서 키에 해당하는 값(스코어)을 O(1)로 찾고, 그 값을 이용해 스킵 리스트에서 랭킹을 조회하는 방식입니다
단점
연결 리스트를 계층적으로 쌓아 관리하기 때문에, 상대적으로 메모리 사용량이 증가한다는 특징이 있습니다.
비유
'색인이 잘 된 백과사전'과 같습니다. 해시 테이블은 우리가 단어를 보고 바로 페이지 번호를 찾는 '색인(Index)' 역할을 하고, 스킵 리스트는 각 장마다 큰 제목과 소제목이 있어 수천 페이지 중 원하는 내용을 순식간에 찾아가게 해주는 '계층적 목차' 역할을 합니다. 여기에 스팬이라는 '누적 페이지 수'가 적혀 있어, 내가 지금 몇 번째 내용을 읽고 있는지 바로 알 수 있는 것과 같습니다.
RDB vs Zset
RDB로 실시간 랭킹을 구현 할 수 있습니다. 하지만, 성능 이슈 및 구현 복잡도 등 다양한 문제가 존재합니다.
정렬 부하 (Sorting Overhead)
- ZSet: 데이터가 저장될 때부터 이미 정렬된 상태로 들어갑니다.
- RDB: 데이터를 읽어올 때마다 ORDER BY 구문을 사용해 정렬 연산을 수행해야 하므로, 데이터 양이 많아질수록 조회 속도가 급격히 느려지고 데이터베이스에 상당한 부하를 줍니다.
실시간 처리 성능 저하
- ZSet: 스킵 리스트 구조 덕분에 데이터 삽입, 삭제, 검색이 모두 O(logN)의 시간 복잡도로 일정하게 빠르게 처리됩니다.
- RDB: 유저가 증가할수록 계산해야 하는 데이터 크기가 배로 늘어나며, 대량의 실시간 업데이트와 정렬을 동시에 처리할 경우 디스크 I/O 발생 등으로 인해 심각한 성능 저하를 초래할 수 있습니다.
구현 로직의 복잡성
- ZSet: 중복 제거, 스코어 업데이트, 자동 정렬, 특정 순위 범위 삭제(ZREMRANGEBYRANK) 등의 기능을 내장 커맨드로 간단히 처리할 수 있습니다.
- RDB: 기존 데이터 존재 여부 확인(Upsert 로직), 검색 시점 기준 소팅, 오래된 기록 삭제를 위한 주기적인 배치(Batch) 작업 등을 개발자가 직접 구현하고 관리해야 합니다.
복합 연산의 어려움
- ZSet: ZUNIONSTORE와 같은 커맨드를 사용해 여러 날짜의 랭킹을 가중치를 주어 합산하는 등의 복합 연산을 매우 간단하게 수행할 수 있습니다.
- RDB: 여러 테이블의 데이터를 조인(Join)하거나 집계(Aggregation)한 뒤 다시 소팅하는 복잡한 쿼리가 필요하며, 이는 대규모 시스템에서 병목 현상의 원인이 됩니다
실시간 랭킹 흐름

1. 이벤트 발행 (Publisher)
- commerce-api에서 상품 조회, 좋아요, 주문 완료/취소 이벤트 발행
- 트랜잭셔널 아웃박스 패턴으로 안정적 발행 보장
2. Kafka 토픽 (4개)
| 토픽명 | 파티션 수 | 이벤트 타입 |
| product-view-events | 3 | 상품 조회 |
| product-like-events | 3 | 좋아요 / 좋아요 취소 (type으로 분리) |
| order-completed-events | 3 | 주문 완료 |
| order-canceled-events | 3 | 주문 취소 |
3. Consumer Groups (1:1 매핑)
- 각 토픽마다 독립적인 Consumer Group 할당
- 메시지 라우팅 오류 방지 및 독립적 offset 관리
4. Concurrency (병렬 처리)
- concurrency(3)
- 각 Consumer Group당 3개 스레드 실행
- 파티션 3개 = 스레드 3개 → 1:1 매핑으로 최적 성능
- 총 12개 스레드 병렬 처리 (4개 그룹 × 3개 스레드)
Kafka Event → Consumer (배치 수신/ACK)
Kafka 배치 리스너로 이벤트 묶음을 받고, 성공 시 배치 단위로 ACK 합니다.
@KafkaListener(
topics = [OutboxEvent.LikeCountChanged.TOPIC],
groupId = "ranking-like-consumer",
containerFactory = KafkaConfig.BATCH_LISTENER,
)
fun consumeLikeEvents(
records: List<ConsumerRecord<Any, Any>>,
acknowledgment: Acknowledgment,
) {
rankingFacade.handleLikeEvents(records)
acknowledgment.acknowledge()
}
랭킹 컨슈머 그룹을 분리한 이유는 다음과 같습니다.
1. 관심사의 분리 (Separation of Concerns)
- ProductMetricsConsumer: DB에 메트릭 집계 저장
- RankingConsumer: Redis ZSET에 실시간 랭킹 점수 업데이트
2. 독립적인 컨슈머 그룹 운영
- 동일 토픽(ViewCountIncreased, LikeCountChanged)을 서로 다른 컨슈머 그룹으로 구독
- ProductMetrics: product-metrics-view-consumer, product-metrics-like-consumer
- Ranking: ranking-view-consumer, ranking-like-consumer
- 같은 이벤트를 각각 독립적으로 처리 (offset 관리 분리)
3. 처리 실패 격리
- Ranking 집계 실패가 ProductMetrics 집계에 영향 없음
- 각 컨슈머의 재시도 정책, 에러 핸들링을 독립적으로 관리
4. 확장성 및 배포 유연성
- 랭킹 컨슈머만 별도로 스케일 아웃 가능
- 메트릭 집계와 랭킹 집계의 처리 속도가 다를 경우 독립적 튜닝 가능
5. 비즈니스 로직 분리
- Ranking은 가중치 기반 점수 계산 (조회 0.1, 좋아요 0.2, 주문 0.7)
- ProductMetrics는 단순 카운팅 집계
- 서로 다른 도메인 로직이므로 컨슈머 분리가 합리적
Service (점수 집계/멱등성 처리)
날짜별/상품별 점수를 누적 집계하고, 배치 내 중복 및 이벤트 중복을 제거합니다.
1. 입력 이벤트 목록이 비어 있으면 종료
2. 배치 내 중복(eventId+aggregateId) 제거
3. DB 멱등성 체크로 이미 처리된 이벤트 스킵
4. 처리 완료를 즉시 기록(중복 방지)
5. 좋아요 점수 계산 후 날짜/상품별로 누적 합산
6. 날짜 키별로 Redis ZSET에 일괄 증가/감소 적용(ZINCRBY)
2번
좋아요 100개의 이벤트를 배치로 한번에 가져왔다.
100개의 이벤트 중 동일한 메시지를 제거 하여 정확히 반영한다.
코드
@Transactional
fun processLikeScoreBatch(
events: List<LikeScoreEvent>,
isIncrement: Boolean,
) {
if (events.isEmpty()) {
return
}
val scoresByDate = mutableMapOf<String, MutableMap<Long, Double>>()
val processedEventKeys = mutableSetOf<String>()
events.forEach { event ->
val aggregateId = "${event.productId}:${event.dateKey}"
// 배치 내 중복 체크 (같은 배치에서 동일 eventId+aggregateId 조합은 1번만 처리)
val eventKey = "${event.eventId}:$aggregateId"
if (processedEventKeys.contains(eventKey)) {
log.debug("배치 내 중복 랭킹 좋아요 이벤트: eventId={}, aggregateId={}", event.eventId, aggregateId)
return@forEach
}
// DB 멱등성 체크
if (eventService.isAlreadyHandled(event.eventId, aggregateId)) {
log.debug("이미 처리된 랭킹 좋아요 이벤트: eventId={}, aggregateId={}", event.eventId, aggregateId)
return
}
// 즉시 처리 완료 기록 (배치 내 중복 방지)
eventService.markAsHandled(event.eventId, aggregateId, event.eventType, event.eventTimestamp)
val score = RankingScoreCalculator.calculateLikeScore()
val productScores = scoresByDate.getOrPut(event.dateKey) { mutableMapOf() }
productScores[event.productId] = (productScores[event.productId] ?: 0.0) + score
processedEventKeys.add(eventKey)
}
// Redis 작업 수행
val actionName = if (isIncrement) "증가" else "감소"
scoresByDate.forEach { (dateKey, productScores) ->
if (productScores.isNotEmpty()) {
if (isIncrement) {
rankingRepository.batchIncrementScores(dateKey, productScores)
} else {
rankingRepository.batchDecrementScores(dateKey, productScores)
}
log.info("랭킹 좋아요 점수 배치 {}: dateKey={}, {} 건", actionName, dateKey, productScores.size)
}
}
}
이벤트 타입별 가중치를 계산합니다.
object RankingScoreCalculator {
private const val VIEW_WEIGHT = 0.1
private const val LIKE_WEIGHT = 0.2
private const val ORDER_WEIGHT = 0.7
/**
* 조회수 점수 계산
* @return 0.1
*/
fun calculateViewScore(): Double {
return VIEW_WEIGHT * 1.0
}
/**
* 좋아요 점수 계산
* @return 0.2
*/
fun calculateLikeScore(): Double {
return LIKE_WEIGHT * 1.0
}
/**
* 주문 점수 계산 (log10 정규화)
* @param price 상품 가격
* @param quantity 주문 수량
* @return 0.7 × log10(price × quantity)
*/
fun calculateOrderScore(price: Long, quantity: Int): Double {
val amount = (price * quantity).toDouble()
return if (amount > 0) {
ORDER_WEIGHT * kotlin.math.log10(amount)
} else {
0.0
}
}
}
주문 가중치에 log10을 사용한 이유는 주문 금액 분포가 큰 시스템이라 생각했고, 점수 폭을 줄여(정규화) 가격 금액이 큰 상품의 주문이 랭킹을 과도하게 지배하지 않게 하려는 목적으로 적용하였습니다.
Redis Repository (Pipeline 배치 업데이트)
같은 날짜 키를 묶어 일자별 키 ranking:all:{yyyyMMdd}에 대해 ZINCRBY를 파이프라인으로 묶어 일괄 반영합니다.
// productScores: Map<Long, Double>
redisTemplate.executePipelined { connection ->
productScores.forEach { (productId, score) ->
val member = toMember(productId)
connection.zIncrBy(key.toByteArray(), score, member.toByteArray())
}
null
}
executePipelined를 사용한 이유는 성능과 네트워크 효율을 높이기 위함입니다.
- 파이프라인 사용: 여러 ZINCRBY를 한 번에 보내서 네트워크 왕복(RTT) 횟수를 줄임 → 처리량↑, 지연↓
- 파이프라인 미사용: 각 상품마다 Redis 호출이 개별 요청/응답으로 나가서 RTT가 N번 발생 → 배치가 커질수록 급격히 느려짐
파이프라인은 원자성 보장(트랜잭션)은 해주지 않고 주로 성능 최적화 목적입니다.
그럼 redis 사용시 원자성 보장은 어떻게 해줄까요? 이번 과제에선 적용하지 않았지만 Lua Script를 사용하면 원자성을 보장할 수 있습니다.
"Redis에서 카운트를 증가시키고, 그 결과를 기반으로 ZSET score를 갱신” 하는 패턴이 있다고 가정 해봅시다.
shell
INCRBY like:count:100 300
ZADD like:ranking <score> 100
code
fun likeConsume(events: List<LikeEvent>) {
val increment = 300L
val targetId = "100"
val countKey = "like:count:$targetId"
val rankingKey = "like:ranking"
val originCount = redisTemplate.opsForValue()
.increment(countKey, increment) ?: 0L
val score = RankingScorer(originCount).score()
redisTemplate.opsForZSet()
.add(rankingKey, targetId, score)
}
- increment()는 증가 된 결과를 반환하며, 해당 값으로 score 점수로 반영합니다.
- 전형적인 read-modify-write 패턴입니다.
- INCRBY는 원자적이지만 그 다음 ZADD는 별도 명령이라 Redis 자체는 싱글 스레드지만 사이에 애플레케이션 레벨에서 다중 인스턴스가 동시에 수행하면 레이스 컨디션이 발생할 수 있습니다.
- originCount는 최신이 아닌 값이 될 수 있고, 그 결과 ZADD가 더 낮은 score로 덮어쓰는 레이스가 생길 수 있습니다.
- 즉, INCRBY와 ZADD 사이에 일관성 깨짐이 발생할 수 있습니다.
- 즉시 일관성 필요하면 Lua로 묶거나 MULTI/EXEC로 같은 트랜잭션에서 처리해야 합니다.
Lua Script
shell
local count = redis.call("INCRBY", KEYS[1], ARGV[1])
redis.call("ZADD", KEYS[2], ARGV[2], ARGV[3])
return count
code
val script = DefaultRedisScript<Long>().apply {
setScriptText(
"""
local count = redis.call("INCRBY", KEYS[1], ARGV[1])
redis.call("ZADD", KEYS[2], ARGV[2], ARGV[3])
return count
""".trimIndent()
)
resultType = Long::class.java
}
fun likeConsume(events: List<LikeEvent>) {
val increment = 300
val targetId = "100"
val score = RankingScorer(/* 미리 계산 or ARGV로 전달 */).score()
redisTemplate.execute(
script,
listOf("like:count:$targetId", "like:ranking"),
increment.toString(),
score.toString(),
targetId
)
}
위 코드는 INCRBY와 ZADD를 하나의 Lua 스크립트로 묶어 원자적으로 실행하는 예시입니다.
- DefaultRedisScript에 Lua 본문을 넣고 resultType = Long으로 반환 타입을 지정합니다.
- 스크립트는 KEYS[1](카운터 키)에 INCRBY를 실행하고, 그 결과를 count로 받습니다.
- 이어서 KEYS[2](랭킹 ZSET)에 ZADD를 호출해 ARGV[2](score)와 ARGV[3](member)를 저장합니다
- redisTemplate.execute(...)는 하나의 Redis EVAL 실행이므로 INCRBY와 ZADD 사이에 다른 쓰기가 끼어들 수 없습니다.
해당 코드의 파라미터 매핑은 이렇게 됩니다:
- KEYS[1] = like:count:$targetId
- KEYS[2] = like:ranking
- ARGV[1] = increment
- ARGV[2] = score
- ARGV[3] = targetId
💡 지금은 score를 애플리케이션에서 미리 계산해서 넘기고 있어서, 동시 업데이트가 있을 때 최신 count 기반 score가 아닐 수 있습니다.
즉시 일관성이 필요하면 score 계산을 Lua 내부로 옮기거나, count를 반환받아 클라이언트에서 다시 계산하지 않도록 만들어야 합니다.
Lua Script 사용 예시로만 이해 해주세요.
랭킹 시스템의 Cold Start 문제 — 윈도우 설계 관점에서 풀어보기
실시간 랭킹을 만들 때 가장 먼저 부딪히는 이슈 중 하나가 콜드 스타트(cold start)입니다.
“윈도우가 바뀌는 순간 랭킹이 비어버린다”는 현상인데, 이 문제는 윈도우 설계 방식과 직결됩니다.
윈도우란 무엇인가?
윈도우는 "어느 기간의 데이터를 집계할 것인가"를 정하는 시간 범위 입니다.
- "오늘 하루 동안" 가장 많이 팔린 상품 → 윈도우 = 1일
- "최근 1주일 동안" 가장 많이 팔린 상품 → 윈도우 = 7일
- "최근 1시간 동안" 가장 많이 본 상품 → 윈도우 = 1시간
텀블링 윈도우 vs 슬라이딩 윈도우
텀블링 윈도우 (Tumbling Window)
고정된 크기의 시간 구간을 연속으로 배치하되, 서로 겹치지 않게 하는 방식입니다.
마치 시계의 시침처럼 "딱딱 끊어지는" 구간입니다.

✅ 장점
1. 구현 단순성
- 날짜/시간 포맷만으로 키 생성 가능
- 복잡한 계산 불필요
2. 성능 우수
- 각 윈도우가 독립적 → 조회 시 단일 키만 읽으면 됨
- 과거 데이터 정리 쉬움 (키 단위로 TTL 설정/삭제)
3. 데이터 정합성
- 하나의 이벤트는 정확히 하나의 윈도우에만 속함
- 중복 집계 불가능
❌ 단점
1. 콜드 스타트
- 윈도우 전환 시점에 랭킹이 비거나 빈약해짐
- 초반 소수 이벤트로 순위가 과도하게 요동침
2. 경계의 딱딱함
- 23:59와 00:00 사이 1초 차이가 완전히 다른 윈도우
- 자연스러운 흐름 부족
콜드 스타트는 왜 생기나?
콜드 스타트는 주로 고정 구간(텀블링 윈도우)에서 발생합니다.
예를 들어 2025년 12월 24일 24:00에 윈도우가 “딱 끊겨” 바뀌기 때문에 새로운 윈도우 시작 순간에는 점수가 0입니다.
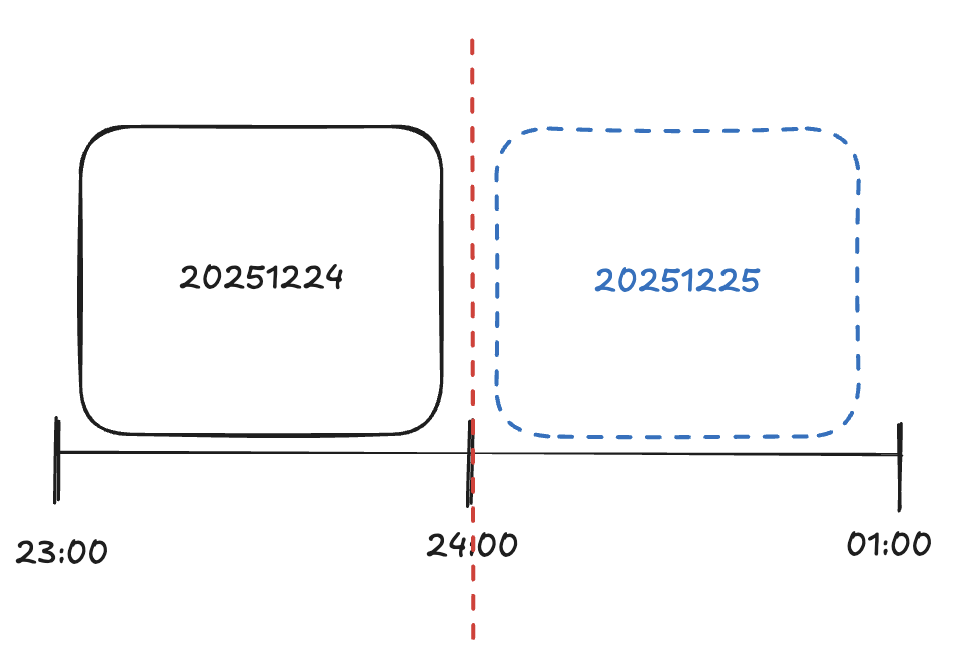
1. 윈도우가 "오늘"로 정의됨 → ranking:all:20251224 키에 점수 누적
2. 자정(00:00)이 되면 → 새로운 날짜가 시작 → ranking:all:20251225 키 사용
3. 새 키는 비어있음 → 아직 아무 이벤트(조회/좋아요/주문)가 발생하지 않았음
4. 결과: 랭킹이 비어버림 ⚠️
2025년 12월 25일 00:00이 되어 랭킹을 조회했을 때는 빈 랭킹 목록이 나올 수 있습니다.
또한, 랭킹 상품 수가 현저히 적어져서, 초반의 랭킹 순위가 심하게 요동칠 것입니다.
carry over

캐리 오버는 단어 의미상 어떤 것을 다음 시기나 단계로 넘기거나 전달하는 것을 의미합니다.
즉, 새 윈도우가 시작되기 전에, 이전 윈도우의 점수 일부를 미리 복사해두는 기법입니다.
마치 "예열(warm-up)"처럼 새 윈도우에 초기값을 심어놓는 것입니다.
랭킹 집계에선 새로운 키 생성시 전날 점수의 일부를 적은 가중치를 곱해 미리 반영합니다.
그림에선 20251225가 되기 10분전에 20251224 랭킹 점수의 10%를 20251225에 반영합니다.
가중치가 너무 높으면(80%) 어제 점수가 너무 강해서 오늘 진짜 인기 상품이 올라오지 못합니다.
가중치가 너무 낮으면(1%) Carry-over 효과가 너무 약해서 여전히 초반 순위가 요동 칩니다.
10~20%가 적당하다고 생각합니다. 전날 인기 상품에 충분한 "버퍼"를 제공하고, 오늘 실제 인기 상품이 올라올 여지는 충분히 남깁니다.
주의해야할 점은 스케줄러가 실행이 안되면 어떻게 대처해야할지 고민해야 합니다. 한두번의 재시도를 적용하고 실패시 Graceful Degradation으로 전날 랭킹을 그대로 노출할 수도 있습니다.
슬라이딩 윈도우 방식을 사용하면 콜드 스타츠 자체가 없습니다.
슬라이딩 윈도우
슬라이딩 윈도우는 고정된 크기의 윈도우(시간 구간)를 시간의 흐름에 따라 연속적으로 이동시키면서 데이터를 집계하는 방식입니다.
텀블링 윈도우와 달리 윈도우가 서로 겹칩니다. 마치 "움직이는 시간 창문"처럼 매 순간 "현재 시점부터 과거 N시간"을 바라봅니다.


슬라이딩 윈도우는 고정된 크기의 윈도우를 시간의 흐름에 따라 이동시키면서 데이터를 집계하는 방식입니다.
예시 (3시간 슬라이딩 윈도우):
- 15:00 시점 → 12:00~15:00 랭킹 데이터
- 16:00 시점 → 13:00~16:00 랭킹 데이터 (12시 데이터가 자연스럽게 빠짐)
- 17:00 시점 → 14:00~17:00 랭킹 데이터
- 18:00 시점 → 15:00~18:00 랭킹 데이터
과거 시간대별로 다른 가중치(10%, 20%, 30%)를 적용하는 방식을 사용할 수도 있습니다.
현재 시간 15:00에 15:00 ~ 16:00 랭킹 생성시 ((12:00 ~ 13:00) x 10%) + ((13:00 ~ 14:00) x 20%) + ((14:00 ~ 15:00) x 30%)]"
✅ 장점
1. 자연스러운 순위 변화
- 특정 시점에 급격한 리셋이 없음
- 오래된 데이터는 점진적으로 윈도우 밖으로 밀려남
- 사용자 경험상 더 부드러운 랭킹 변화
2. 콜드 스타트 없음
- 자정이 되어도 지난 23시간 데이터가 여전히 포함됨
- 새로운 윈도우가 "비어있는" 상태가 아님
- 초반 소수 이벤트로 인한 순위 왜곡 방지
3. 실시간성
- "지금 이 순간 기준 최근 N시간" 개념이 명확
- 시간 경계가 인위적이지 않고 연속적
❌ 단점
1. 구현 복잡도 높음
- 시간 단위로 세밀한 데이터 관리 필요
- Redis 구현 시: 시간대별 ZSET 여러 개 + ZUNIONSTORE 필요
- 또는 타임스탬프 기반 Score 설계 + ZREMRANGEBYSCORE로 만료 처리
2. 성능 오버헤드
- 조회 시마다 여러 키를 병합(Union)하거나 필터링 필요
- 텀블링 윈도우의 단일 키 조회보다 느림
- 실시간 집계 시 계산량 증가
3. 메모리 사용량 증가
- 동일 이벤트가 여러 윈도우에 중복 저장될 수 있음
- 예: 15:30 이벤트 → 16시, 17시, 18시 윈도우 모두에 포함
- 세밀한 TTL 관리 필요
슬라이딩 윈도우는 왜 콜드 스타트가 없을까?
경계가 없다
텀블링 윈도우의 문제는 명확한 경계입니다. 12월 24일 23:59:59까지는 어제 랭킹, 12월 25일 00:00:00부터는 오늘 랭킹. 이 순간 모든 점수가 리셋되고, 어제까지 1위였던 상품도 자정에 갑자기 사라집니다.
슬라이딩은 데이터가 한 번에 사라지지 않고 점진적으로 밀려나기 때문에 콜드 스타트가 없습니다.
점진적인 변화
텀블링 윈도우:
23:59 → 1,200점 (1위)
00:00 → 0점 (순위 없음) 💥
슬라이딩 윈도우:
23:00 → 1,200점 (20~23시 합산)
00:00 → 1,000점 (21~00시 합산) ✅
01:00 → 600점 (22~01시 합산)
03:00 → 180점 (00~03시 합산)
자정이 지나도 어제 21시, 22시, 23시 데이터가 윈도우에 남아있어 점수가 서서히 감소합니다. 절벽이 아닌 완만한 경사입니다.
완화이지 해결은 아니다
슬라이딩 윈도우도 결국 시간이 지나면 데이터가 사라집니다. 다만 00시 정각에 "즉시" 사라지는 게 아니라 몇 시간에 걸쳐 "점진적으로" 밀려난다는 차이입니다.
사용자는 "방금까지 1위였던 상품이 왜 갑자기 없지?"라는 의문 대신, 자연스러운 순위 변화를 경험합니다.
차이점:
- 텀블링: 자정에 즉시 0점 (0.1초 만에 사라짐)
- 슬라이딩: 24시간에 걸쳐 점진적으로 0점 (서서히 사라짐)
텀블링:
23:50 앱 켬 → "무선 이어폰" 1위
00:10 앱 켬 → "무선 이어폰" 없음 😱
슬라이딩:
23:50 앱 켬 → "무선 이어폰" 1위 (1,200점)
00:10 앱 켬 → "무선 이어폰" 1위 (1,200점) ← 여전히 유효
06:00 앱 켬 → "무선 이어폰" 2위 (1,200점) ← 새 상품들이 부상
12:00 앱 켬 → "무선 이어폰" 5위 (1,200점) ← 점차 내려감
18:00 앱 켬 → "무선 이어폰" 10위 (1,200점)
20:01 앱 켬 → "무선 이어폰" 순위 밖 (점수 감소 시작)
텀블링과 슬라이딩 정리
| 항목 | 텀블링 | 슬라이딩 |
| 자정의 의미 | 윈도우 경계 (리셋 시점) | 평범한 1분 (특별함 없음) |
| 데이터 소멸 | 00:00에 한 번에 사라짐 | 24시간에 걸쳐 점진적 소멸 |
| 콜드 스타트 | 발생 (자정에 랭킹 비움) | 없음 (자정에도 데이터 유지) |
| 사용자 경험 | 자정 전후 단절감 | 자연스러운 흐름 |
| 운영 복잡도 | 쉬움 (단일 키) | 어려움 (시간별 키 합산) |
대용량 트래픽에서 랭킹 설계
트래픽이 적어 실시간으로 처리해도 문제가 없다면 zset에 바로 접근하여 ZINCRBY를 쓰는 방식이 가장 단순합니다.
현재 consumer에서 zset에 score를 반영하고 있는데, publisher에서 zset에 바로 접근해도 됩니다.
하지만 트래픽이 많다면 쓰기 부하를 줄이기 위한 관점으로 설계를 해야합니다.
쓰기 부하 줄이기/지연 허용
redis나 rdb 등 저장소에 누적하고, 별도로 zset에 score을 반영하는 방식이 유효합니다. 다만 랭킹이 최종값 기준으로 주기적으로 갱신 되어 초 실시간은 보장이 되지 않습니다.
그렇다면, zset에 언제 어떻게 반영할까요?
- 주기적으로 배치를 돌려서 반영(예: 스케줄러가 GET해서 ZADD)
- 이벤트를 발행하여 별도 컨슈머 에서 zset에 score 반영
스케줄러 주기는 어떻게 할지, 이벤트 발행은 어느 시점에 할지 고민을 해야 합니다.
방법론은 많습니다. 상황에 맞는 방법을 찾고 적용하며, 합리적인 이유로 설명할 수 있는것이 곧 엔지니어링의 능력인 것 같습니다.
루프백 3기 오픈
https://www.loopers.im/education
교육 과정 | Loop:Pak
Loop:Pak 부트캠프 교육 과정 상세 정보. NextNode Backend Edition을 포함한 전문 개발자 양성 커리큘럼과 현업 멘토링 프로그램을 만나보세요.
www.loopers.im
루퍼스 3기가 오픈되었습니다.
추천인 코드를 입력하면 할인가로 수강할 수 있습니다. 다만 결코 작은 금액은 아니기에, 신청 전 적지 않은 고민을 했는데요. AI 기술의 빠른 발전과 함께 연차가 쌓이면서, 스스로의 실력에 대한 의구심이 들던 시기였습니다.
며칠간 고민한 끝에 이번 기회를 마지막이라 생각하고 수강을 결정했습니다. 지금 돌이켜보면, 후회 없는 선택이었다고 자신 있게 말할 수 있습니다.
만약 저와 비슷한 고민을 하고 있거나, 루퍼스 과정에 대해 궁금한 점이 있다면 언제든지 편하게 연락 주셔도 좋습니다.
LinkedIn 또는 jikimee64@gmail.com으로 언제든 문의 부탁 드립니다. 감사합니다.
추천인 코드
TZFI0
'외부활동 > 루퍼스 2기' 카테고리의 다른 글
| [Loop:PAK] 10주차 WIL (0) | 2025.12.29 |
|---|---|
| [Loop:PAK] 9주차 WIL (0) | 2025.12.21 |
| [Loop:PAK] 8주차 WIL (0) | 2025.12.16 |
| [루퍼스/루프백 2기] Kafka At-Least-Once 전송과 Consumer 멱등성 구현기 (0) | 2025.12.16 |
| [Loop:PAK] 7주차 WIL (0) | 2025.12.06 |