TL;DR
- 개발 먼저 하지 말고, 문서를 먼저 만들어라.
- 코드를 치면서 고민하고 논의하는 것보다, 문서를 먼저 작성하고 코드에 집중하는 것이 효율적이다.
- 요구사항 정의서, 유비쿼터스 언어, 시퀀스 다이어그램, 클래스 다이어그램, ERD를 작성하면 개발은 그대로 옮기기만 하면 된다.
- 문서는 나 자신과 동료, 그리고 미래의 후임자를 위한 최고의 선물이다.
문서화가 필요한 이유
문서화의 핵심 목적은 커뮤니케이션입니다.
"혼자 개발하면 문서화가 필요 없지 않나요?"라고 반문할 수 있지만, 그렇지 않습니다.
인간의 기억력은 유한합니다. 코드든 문서든 작성하는 순간부터 레거시가 되며, 기록하지 않으면 시간이 지나면서 머릿속에서 휘발됩니다.
평생 혼자 개발할 것이 아니라면 언젠가 동료가 생길 것이고, 잘 작성된 문서는 회사의 귀중한 자산이 됩니다.
문서화를 통해 얻을 수 있는 것들은 다음과 같습니다
- 지식의 공유와 보존: 개발 히스토리와 비즈니스 맥락을 후임자에게 전달
- 의사결정 근거 기록: "왜 이렇게 만들었지?"에 대한 답
- 커뮤니케이션 효율성: 반복적인 설명 대신 문서 공유
- 협업 품질 향상: 팀원 간 이해도 격차 해소
가치 있는 문서란?
단순히 "무엇을 했다"를 적는 것이 아니라,
"왜 그렇게 결정했는지, 어떤 대안이 있었는지, 무엇을 고민했는지" 를 담고 있는 문서입니다.
즉, 의사결정의 이유, 실패했던 접근, 고려했던 대안들까지 담겨 있어야 시간이 지나도 “왜 이렇게 만들었는지” 이해할 수 있습니다.
실무에서 유용한 ‘가치 있는 문서’ 예시
| 문서 종류 | 내용 예시 | 가치를 주는 이유 |
| ADR (Architecture Decision Record) | “우리는 인증 방식으로 OAuth2 대신 JWT를 선택했다. 이유는 외부 연동 필요성과 무상태 서버 요구 조건 때문이었다.” | 미래에 왜 특정 기술을 선택했는지 맥락을 빠르게 파악 가능 |
| 기능 설계서 (with 트레이드오프) | “좋아요 수는 실시간 반영을 위해 Redis를 사용하고, 데이터 유실 방지를 위해 Kafka + RDB batch를 병행한다.” | 성능과 정합성 사이의 고민을 드러내고, 이후 시스템 변화에 대응할 수 있게 함 |
| 장애 보고서 (Postmortem) | “DB CPU 100% → 캐시 미스 급증 → Redis TTL 미설정이 원인. 향후 캐시 warm-up 정책 도입 예정” | 같은 실수를 반복하지 않게 하며, 개선 내역을 투명하게 공유 가능 |
제가 만든 문서는 다음과 같습니다
- 요구사항 정의서
- 유비쿼터스 언어
- 시퀀스 다이어그램
- 클래스 다이어그램 & 도메인 모델
- ERD
요구사항 정의서
실무에서 업무를 명확하게 내려주는 경우가 없습니다. 가령 다음과 같이 내려온다고 가정합니다.
사용자는 쿠폰을 발급받고, 여러 상품을 한 번에 주문하고 결제합니다.
여러 브랜드의 상품을 둘러보고, 마음에 드는 상품엔 좋아요를 누를 수 있습니다.
여태까지 이러한 요구사항만 받고 바로 코딩을 시작했었습니다.
개발하면서 예외사항이 생기면 그때그때 비즈니스 규칙을 정하고, 따로 문서를 만들지 않습니다.
기획자가 준 내용과 피그마만 보고 구현하는 방식입니다. 개발이 끝나고 N개월이 지난 후, 관련 기능에 대한 문의가 들어옵니다.
문제는 이때부터입니다.
당시 정했던 비즈니스 규칙이 기억이 나질 않아 코드를 일일이 뒤져가며 파악해야 했습니다.
이런 문제를 겪고 나서, 요구사항 문서만 보고도 모든 것을 알 수 있도록 상세하게 작성하기로 했습니다.
개발자는 위 사항을 받고 요구사항을 정제된 문장으로 정의하고 다양한 시나리오를 고려해서 요구사항을 상세하게 작성하기로 했습니다.
요구사항 문서만 보고도 구현에 지장이 없도록요. 아래와 같은 시나리오를 고려할 수 있습니다.
- 여러 상품 주문 중 일부 상품만 재고 부족 → 전체 주문 취소? 부분 주문 허용?
- 장바구니 담은 후 시간이 지나 재고 소진 → 주문 시점에 재검증 필요
- 네트워크 타임아웃으로 결제 결과 미수신 → 중복 결제 방지 및 상태 확인 로직
- 사용자가 좋아요 버튼 연속 클릭 → 중복 요청 처리 (멱등성)
아래는 제가 작성한 좋아요 기능의 요구사항 문서 예시입니다.
3. 좋아요
3.1 유저 스토리
* 사용자는 마음에 드는 상품에 좋아요를 누를 수 있다.
* 사용자는 이미 좋아요한 상품의 좋아요를 취소할 수 있다.
* 사용자는 자신이 좋아요한 상품 목록을 조회할 수 있다.
* 좋아요 등록/취소는 멱등하게 동작해야 한다.
3.2 기능 명세
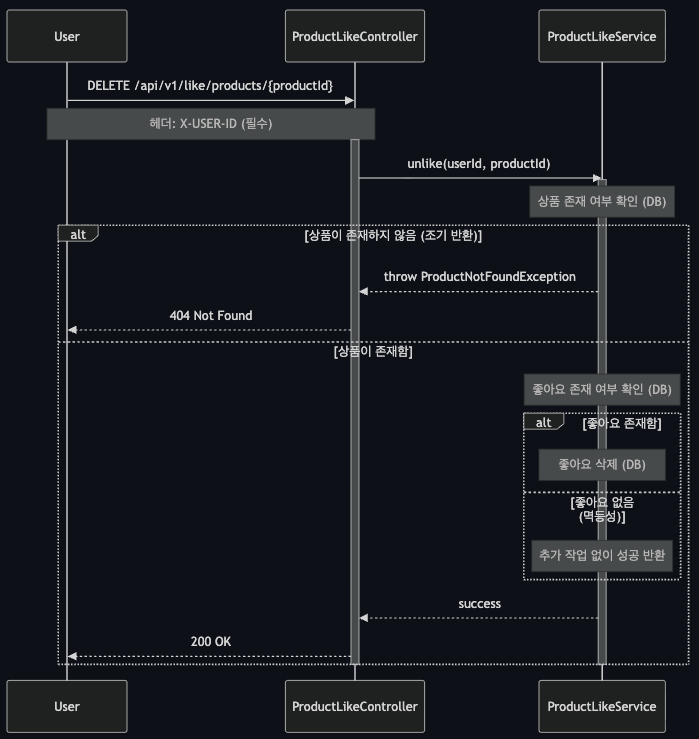
3.2.1 상품 좋아요 등록 (POST `/api/v1/like/products/{productId}`)
[Main Flow]
1. 클라이언트가 X-USER-ID 헤더와 productId를 포함하여 요청을 전송한다.
2. 시스템은 사용자와 상품의 존재 여부를 확인한다.
3. 시스템은 이미 좋아요가 존재하는지 확인한다.
4. 좋아요가 없는 경우, 좋아요를 생성하고 상품의 좋아요 수를 증가시킨다.
5. 좋아요 등록 성공 응답을 반환한다.
[Alternate Flow - 이미 좋아요가 존재하는 경우]
* 시스템은 이미 좋아요가 존재함을 확인한다.
* 추가 작업 없이 성공 응답을 반환한다. (멱등성 보장)
[Exception Flow]
* E1. X-USER-ID 헤더가 없는 경우: 401 Unauthorized 반환
* E2. 사용자가 존재하지 않는 경우: 404 Not Found 반환
* E3. 상품이 존재하지 않는 경우: 404 Not Found 반환
[비즈니스 규칙]
* 한 사용자는 동일 상품에 대해 최대 1개의 좋아요만 가능
* 좋아요는 실시간으로 상품의 좋아요 수에 반영
* 동일 요청을 여러 번 보내도 결과는 동일 (멱등성)
유저 스토리를 자연어로 작성하였습니다.
유스 케이스 흐름을 Main Flow, Alternate Flow, Exception Flow로 나눠서 작성하였습니다.
Main Flow는 정상적인 시나리오의 흐름을 단계별로 기술합니다.
Alternate Flow는 Main Flow의 변형으로, 정상 범위 내에서 다른 경로를 따르는 시나리오를 나타냅니다.
Exception Flow는 오류 상황이나 예외 케이스를 처리하는 흐름입니다.
마지막으로 비즈니스 규칙까지 추가하였습니다.
유비쿼터스 언어
유비쿼터스 언어란 팀 전체가 공유하는 공통 언어로, 문서, 회의, 대화, 코드 등 모든 영역에서 일관되게 사용되는 용어 체계입니다.
유비쿼터스 언어가 중요한 이유
최근 회의에서 유비쿼터스 언어의 중요성을 실감한 경험이 있습니다.
대표님이 "타사의 비딩 금액을 주기적으로 체크해서 우리 제품이 항상 TOP 3 안에 노출되도록 해주세요"라고 요청하셨습니다.
처음에는 '비딩 금액'이 무엇인지 이해가 안 되었습니다. 알고 보니 '광고 입찰가'를 의미하는 용어였습니다.
만약 팀 내에서 이 용어를 명확히 정의하고 공유했다면, 회의 중에 혼란 없이 바로 이해할 수 있었을 것입니다.
용어가 통일되지 않으면 발생하는 문제는 다음과 같습니다.
- 같은 개념을 다르게 부르며 소통 비용 증가
- 코드와 문서의 용어 불일치로 혼란 가중
- 신규 팀원의 온보딩 시간 증가
이런 경험을 통해 유비쿼터스의 중요성을 깨달았고, 이커머스 요구사항을 기반으로 다음과 같이 추출하였습니다.
| 한국어 | 영어 | 설명 |
| 회원 | User | 회원가입을 완료한 사용자 |
| 브랜드 | Brand | 상품을 제공하는 판매 브랜드 |
| 상품 | Product | 판매 가능한 개별 품목 |
| 재고 | Stock | 상품별 보유 수량 정보 |
| 주문 | Order | 회원이 상품을 구매하기 위해 생성한 주문 건 |
| 주문상품 | OrderItem | 주문에 포함된 개별 상품 항목 |
| 포인트 | Point | 회원이 주문 시 결제 수단으로 사용 가능한 적립금 |
| 좋아요 | Like | 회원이 관심 있는 상품을 표시하는 기능 |
시퀀스 다이어그램
시퀀스 다이어그램은 객체 간 메시지 흐름을 시각화하여 책임과 협력을 표현하는 도구입니다.
시퀀스 다이어그램이 중요한 이유
"누가 무엇을 책임지는가"를 명확히 파악할 수 있습니다.
코드보다 빠르게 흐름 구조를 파악하고 공유할 수 있어서, 팀 내 협업(특히 프론트엔드 ↔ 백엔드 ↔ 기획자 간) 커뮤니케이션의 기반이 됩니다.
작성 방법
저는 다음과 같이 작성했습니다.
기능 하나당 하나의 시퀀스 다이어그램을 만들었습니다.
예를 들어, 사용자 → Controller → Application → Domain 계층 순으로 흐름을 표현했습니다.
다만 Repository 계층까지는 표현하지 않았습니다. Participant가 불필요하게 많아지면 오히려 핵심 흐름이 보이지 않기 때문입니다.
도구는 Mermaid를 사용했습니다.
Lucidchart도 많이 사용한다고 하는데, 더 예뻐 보여서 나중에 공부해서 적용해봐야겠습니다.
주문 요청의 시퀀스 다이어그램이 가장 복잡했습니다.
예외 처리 사항도 많고, 주문 생성 시 만들어야 할 객체도 많습니다. 마지막에는 외부 시스템에 주문서도 전달해야 합니다.
예외 사항은 early return을 사용하여 복잡성을 줄였습니다.
activate bar도 표기하였습니다.
activate bar는 객체가 활성화된 시간(메서드 실행 중인 기간)을 시각적으로 보여줍니다. 이를 통해 어느 구간에서 처리 시간이 오래 걸리는지, 어떤 객체가 동시에 활성화되는지를 한눈에 파악할 수 있습니다.
주의할 점
시퀀스 다이어그램을 처음부터 실제 코드 구조와 최대한 일치하게 그려야 합니다.
그렇지 않으면 시퀀스와 실제 구현이 따로 놀아서 유지보수가 불가능해집니다.
코드를 수정할 때마다 다이어그램도 함께 수정해야 하는데, 처음부터 구조를 맞춰놓지 않으면 나중에 더 큰 번거로움이 생깁니다.
너무 많은 세부 흐름을 넣지 마세요.
시퀀스 다이어그램이 복잡해지면 오히려 핵심 흐름을 파악하기 어렵습니다.
도메인 객체 간 메시지를 표현하세요.
Service만 호출하는 구조가 아니라, 도메인 객체들이 어떻게 협력하는지를 보여줘야 합니다.
다음은 좋아요 등록 기능을 시퀀스 다이어그램으로 작성한 예시입니다.
클래스 다이어그램
클래스 다이어그램은 시스템을 구성하는 객체 간 구조와 책임을 시각화한 설계 도구입니다.
클래스 다이어그램이 중요한 이유
도메인 개념 간 책임과 관계를 시각화할 수 있습니다.
설계에서 코드로 전환할 때 자연스럽게 연결되며, 패키지 구조와 의존성 구조 설계의 기준이 됩니다.
작성 방법
저는 클래스 다이어그램에 모든 필드를 표현하지 않았습니다.
생성일시, 수정일시 같은 공통 필드는 제외했습니다.
이유는 도메인 개념 간 책임과 관계만을 중점적으로 시각화하기 위해서입니다.
모든 필드를 넣으면 오히려 핵심 구조가 보이지 않습니다. 지나친 복잡도는 오히려 설계의 본질을 흐릴 수 있습니다.
비즈니스 책임은 도메인 객체에 포함시켰습니다.
Service에 모든 로직을 집중시키지 않고, 도메인 객체가 스스로 책임을 지도록 설계했습니다.
설계 후에는 "한 객체에 책임이 과도하게 몰리지 않았는가?"를 점검했습니다.
설계 시 고민했던 사항
1. Stock (재고 관리)
결정: 비관적 락 사용
재고의 테이블을 별도로 분리했습니다. 재고의 정합성을 지키기 위해 락을 걸어야 했습니다.
낙관적 락과 비관적 락 중 어떤 것을 선택할지 고민했습니다.
낙관적 락의 문제점
성능 이슈: 인기 상품에 동시 주문 100건이 발생할 경우, 재시도 로직(3회)으로 인해 최악의 경우 N × 3 트랜잭션이 발생합니다.
정합성 이슈: 멀티 서버 환경에서 Lost Update가 발생할 수 있다고 합니다.
재고 10개인 상품에 주문 12개가 성공하거나, 극단적으로 2개만 성공하는 상황이 발생할 수 있습니다.
비관적 락 선택 이유
- DB 레벨에서 확실한 정합성 보장
- 재시도 로직이 불필요해서 성능 예측 가능
- 현재 트래픽 규모에서는 정합성이 성능보다 더 중요
트레이드오프
락 대기가 발생할 수 있습니다. 트래픽이 증가하면 Redis 기반 분산 락으로 전환을 고려해야 합니다.
2. ProductLike (상품 좋아요)
결정 1: Product에서 likeCount 분리
처음에는 Product 테이블에 likeCount 컬럼을 두려고 했으나, 분리하기로 결정했습니다.
분리 이유
관심사 분리: likeCount는 Product의 본질적 속성이 아닌 사용자 행동 데이터입니다.
락 경합 문제 (Critical): 좋아요 수 업데이트 시 Product 전체 row에 락이 발생합니다. 상품 가격 수정(핵심 비즈니스 로직)이 좋아요 때문에 blocking되는 것은 부자연스럽습니다.
확장성: 좋아요 관련 기능이 추가될 때마다 Product 테이블의 복잡도가 증가하는 것을 방지할 수 있습니다.
결정 2: 좋아요 수 조회 방식
초기 설계: GROUP BY 집계 쿼리를 사용할 예정입니다. 구현은 간단하지만 상품 목록 조회 시 매번 집계 연산을 해야 합니다.
향후 개선 방향 (트래픽 증가 시):
- Step 1: ProductLikeCount 테이블 추가 (단순 JOIN으로 조회)
- Step 2: Redis 캐시 적용
3. VO (Value Object)
결정: 초기 설계 제외, 필요 시 점진적 추가
초기에는 복잡도를 낮추고 빠른 구현을 우선했습니다.
VO를 테이블처럼 다루려는 시도(예: Price를 별도 DB로 설계)는 피했습니다.
VO 추가 신호
다음과 같은 상황이 반복되면 VO로 추출합니다:
- 동일 검증 로직 반복
- 비즈니스 규칙 명확화 필요
- 도메인 개념 구체화
향후 후보
- Price
- Quantity 등
4. 좋아요 삭제 전략
하드 딜리트와 소프트 딜리트 중 선택해야 했습니다.
하드 딜리트
- 장점: DB에서 실제로 삭제되어 저장 공간 절약, 조회 성능 우수
- 단점: 삭제된 데이터 복구 불가능, 감사 추적(audit) 어려움
소프트 딜리트
- 장점: 데이터 복구 가능, 삭제 이력 추적 가능, 실수로 삭제한 데이터 복원 용이
- 단점: 저장 공간 지속적으로 증가, 조회 시 삭제 필터링 필요로 성능 저하
선택: 하드 딜리트
좋아요는 비즈니스 크리티컬한 데이터가 아니고, 삭제 이력을 추적할 필요성이 낮다고 판단했습니다.
하드 딜리트 선택 시 예상되는 문제점
쓰기 문제: 고객센터 문의로 "좋아요 N만 개 다 지워주세요"라는 요청이 들어오면 점진적으로 지워야 합니다. 대량 삭제 시 deleted_at만 업데이트하면 되지만, 이후 실제 데이터 정리(hard delete)를 위한 배치 작업이 필요합니다.
소프트 딜리트 선택 시 예상되는 문제점
읽기 문제: 삭제된 데이터가 계속 쌓이면 조회 시 WHERE deleted_at IS NULL 조건이 항상 필요하고, 인덱스 효율이 떨어져 성능이 저하됩니다.
참고: 트위터의 좋아요 처리 방식
트위터는 대규모 좋아요 데이터를 처리하기 위해 이벤트 소싱 방식을 활용합니다. 좋아요/취소를 이벤트로 기록하고, 집계 데이터는 별도로 관리하여 조회 성능을 최적화합니다.
이 방식은 삭제 이력도 보관하면서 조회 성능도 유지할 수 있지만, 구현 복잡도 높습니다.
추후에 공부를 해봐야 겠습니다.
ERD
ERD는 데이터 간 관계를 정의하여 테이블 구조와 제약을 표현하는 모델입니다.
ERD가 중요한 이유
도메인 모델의 물리적 구현 기반이 됩니다.
성능 이슈(조회 쿼리, 인덱스 등)와 직결되며, API, 도메인, DB 간 구조 일관성 유지에 핵심 역할을 합니다.
작성 방법
ERD는 클래스 다이어그램을 기반으로 작성하였으며, 필요한 PK, UNIQUE INDEX, INDEX를 설계하였습니다.
생성일시(created_at), 수정일시(updated_at), 삭제일시(deleted_at)를 추가하였고, 참조키는 구분되어 지도록 prefix로 ref_를 붙였습니다.
원래는 삭제 시 deleted_yn을 true/false로 컨트롤하는 방식을 사용했는데, deleted_at의 null 여부로 삭제 여부를 판단하는 방식(soft delete)도 있다고 해서 한번 적용해볼 예정입니다.
주의할점
비즈니스 흐름을 반영해야 합니다.
정규화만 추구하면 안 됩니다. 중복 데이터 제거에만 집중하면 조회 시 JOIN이 과도해져서 오히려 성능이 저하됩니다.
FK를 사용하지 않는 이유
데이터 이관의 어려움
CS 문의로 긴급하게 데이터를 수정해야 하는데 FK 제약 때문에 데이터 삭제가 안 되는 상황이 발생할 수 있습니다.
대규모 트래픽 시 성능 문제 및 데드락 위험
FK는 INSERT, UPDATE, DELETE 시 참조 무결성을 검증하기 위해 추가적인 잠금과 검증 작업이 발생합니다. 대규모 트래픽 환경에서는 이러한 오버헤드가 누적되어 병목 지점이 될 수 있습니다.
또한 부모 테이블에서 데이터를 삭제할 때 자식 테이블의 참조 데이터를 모두 확인해야 하므로, 대량 데이터 삭제 작업 시 성능이 크게 저하됩니다.
특히 FK가 있으면 부모-자식 테이블 간 참조 관계 검증 시 여러 테이블에 동시에 락이 걸립니다. 예를 들어, A 트랜잭션이 부모 테이블을 수정하면서 자식 테이블을 참조하고, B 트랜잭션이 자식 테이블을 수정하면서 부모 테이블을 참조하는 경우 데드락이 발생할 수 있습니다.
샤딩 환경에서의 제약
데이터베이스를 샤딩(Sharding)해야 하는 상황에서 FK는 큰 걸림돌이 됩니다.
외래키 제약은 같은 데이터베이스 인스턴스 내에서만 동작하기 때문에, 부모 테이블과 자식 테이블이 서로 다른 샤드에 분산되면 FK를 유지할 수 없습니다.
확장성을 고려한다면 FK 없이 설계하는 것이 유리합니다.
마무리: 학습 후 느낀 점
문서를 작성해보면서 깨달은 가장 큰 인사이트는 "문서화만 잘되어 있으면 코드는 그대로 옮기기만 하면 되는구나"였습니다.
문서화가 가져온 변화
기존 방식의 문제점
코드를 치다가 예외 상황을 발견하면 멈추고, 기획자나 동료와 논의하고, 다시 코드를 수정하고...
이러한 과정이 반복되면 컨텍스트 스위칭으로 인해 작업 효율이 크게 떨어졌습니다.
문서화 우선 접근의 장점
처음에 고생하더라도 문서화를 먼저 완성해놓으면, 이후에는 문서를 보고 그대로 구현하면 됩니다.
온전히 코드 작성에만 집중할 수 있습니다.
문서 유지보수의 중요성
물론 문서도 최신화하지 않으면 코드와 불일치로 인해 혼란에 빠질 수 있습니다.
잘못된 문서는 없는 것보다 못합니다.
수정사항이 생기면 나 자신과 이걸 볼 후임자를 위해서라도 문서를 반드시 함께 수정해야겠습니다.
마치며
인정받는 개발자의 특징 중 하나는 문서화를 잘한다는 것입니다.
저도 현 회사에 입사했을 때 가장 인상 깊었던 점은 백엔드를 혼자 개발하시던 동료 개발자가 문서화를 굉장히 잘해놓으셨다는 것입니다.
덕분에 온보딩 기간이 크게 단축되었고, 레거시 코드를 이해하는 데 큰 도움이 되었습니다.
이번에 작성한 문서 말고도 ADR, 상태 다이어그램 등 다양한 문서들이 있습니다.
앞으로 제가 개발하는 모든 업무에 대해서는 문서를 적극적으로 작성하려고 합니다:
루프백 3기 오픈
https://www.loopers.im/education
교육 과정 | Loop:Pak
Loop:Pak 부트캠프 교육 과정 상세 정보. NextNode Backend Edition을 포함한 전문 개발자 양성 커리큘럼과 현업 멘토링 프로그램을 만나보세요.
www.loopers.im
루퍼스 3기가 오픈되었습니다.
추천인 코드를 입력하면 할인가로 수강할 수 있습니다. 다만 결코 작은 금액은 아니기에, 신청 전 적지 않은 고민을 했는데요. AI 기술의 빠른 발전과 함께 연차가 쌓이면서, 스스로의 실력에 대한 의구심이 들던 시기였습니다.
며칠간 고민한 끝에 이번 기회를 마지막이라 생각하고 수강을 결정했습니다. 지금 돌이켜보면, 후회 없는 선택이었다고 자신 있게 말할 수 있습니다.
만약 저와 비슷한 고민을 하고 있거나, 루퍼스 과정에 대해 궁금한 점이 있다면 언제든지 편하게 연락 주셔도 좋습니다.
LinkedIn 또는 jikimee64@gmail.com으로 언제든 문의 부탁 드립니다. 감사합니다.
추천인 코드
TZFI0
'외부활동 > 루퍼스 2기' 카테고리의 다른 글
| [Loop:PAK] 3주차 WIL (0) | 2025.11.14 |
|---|---|
| [루퍼스/루프백 2기] 도메인을 보호하고 객체간 협력을 지키는 구현 방법 (0) | 2025.11.12 |
| [Loop:PAK] 2주차 WIL (0) | 2025.11.06 |
| [Loop:PAK] 1주차 WIL (0) | 2025.10.30 |
| [루퍼스/루프백 2기] 테스트 코드와 TDD에 대한 나의 생각 (0) | 2025.10.28 |