안녕하세요.
회사에서 배치를 돌려 약 10만건 정도의 데이터를 삽입해야 했습니다.

1번과 2번에서 데이터를 조회 하여 데이터를 합친 후 DB에 저장하는 단순한 프로세스 였습니다.
DB에 저장시 save()를 사용했다가 반나절 이상이 걸렸습니다.
save()를 사용하지 않고 saveAll()로 처리 하였더니 시간이 삼분의 일로 줄어 들었습니다.
이번 기회에 Jpa에서 데이터를 저장하는 방법인 save() / saveAndFlush() / saveAll()의 차이점 대해 정리하려고 합니다.
※ 사실 벌크 삽입은 Spring JDBC의 JdbcTemplate를 이용하면 훨씬 빠르게 Batch Insert를 수행할 수 있습니다.
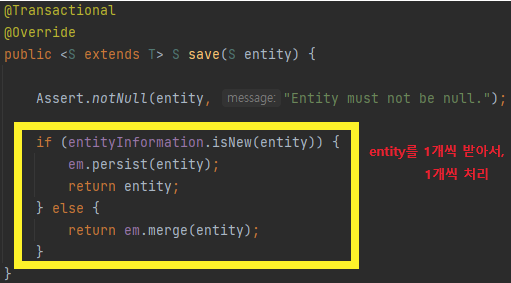
save
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
1건의 엔티티를 디비에 저장할 때 사용 합니다.
로직 순서는 다음과 같습니다. (Mysql의 Auto Increment를 사용한다고 가정)
1. isNew()를 호출하여 엔티티의 기본 키값이 영속성 컨텍스트에 없는 새로운 엔티티인지 확인
2. 새로운 엔티티일 경우 영속성 컨텍스트에 저장
3. 기존 엔티티일 경우 merge를 호출하여 Detached 상태의 엔티티를 영속성 컨텍스트에 반영
save를 호출 하면 영속성 컨텍스트에 엔티티를 보관하고 있다가 트랜잭션이 종료되면 commit이 호출 될때 flush가 발생하여 데이터베이스에 데이터를 저장합니다.
이러한 SQL의 지연된 실행은 성능 최적화를 위한 메커니즘입니다.
간혹 엔티티 데이터를 변경 후 save()를 호출하는데 이는 리소스 낭비차원으로 볼 수 있습니다.
왜나하면 호출하지 않아도 트랜잭션이 유지되는 환경에서의 변경사항은 트랜잭션이 커밋되거나 flush가 호출될 때 DB에 반영이 됩니다.
별도의 save()를 호출 하면 불필요하게 엔티티의 상태를 다시 확인하고, 영속성 컨텍스트에 이미 있는 엔티티를 다시 병합하는 과정을 거치기 때문입니다.
saveAndFlush
@Transactional
@Override
public <S extends T> S saveAndFlush(S entity) {
S result = save(entity);
flush();
return result;
}save() 메소드를 호출 한 후 전체 영속성 컨텍스트를 강제로 flush 합니다.
단점으로는 아래와 같습니다.
1. 관리 중인 엔티티에 대해 변경 사항을 확인하고(더티 체킹) 필요한 SQL 문을 실행하는 과정에서 추가적인 연산이 필요합니다.
2. 트랜잭션 커밋전에 호출하여 네트워크 오버헤드를 줄이는 과정이 생략되어 배치 최적화를 사용할 수 없습니다.,
saveAndFlush를 사용해야 하는 상황은 다음과 같습니다.
1. 특정 엔티티를 저장하고 이어지는 로직에서 영속화된 상태를 DB에서 확인해야 할 때
2. 테스트 또는 디버깅 과정에서 데이터베이스에 대한 변경사항을 즉시 확인하고 싶을 때
트랜잭션이 끝나지 않아 아직 commit이 되지 않았지만 명시적으로 flush를 호출했을 경우에는 한가지 주의 사항이 있습니다. 트랜잭션 격리 수준이 READ_UNCOMMITTED가 아닌 이상 변경 사항이 외부 트랜잭션에는 표시 되지 않습니다.
saveAll
@Transactional
@Override
public <S extends T> List<S> saveAll(Iterable<S> entities) {
Assert.notNull(entities, "Entities must not be null!");
List<S> result = new ArrayList<>();
for (S entity : entities) {
result.add(save(entity));
}
return result;
}N건 이상의 엔티티를 일괄로 저장할 때 사용 합니다.
save vs saveAll 성능 차이
save()와 saveAll () 의 성능 차이에 대해서 알아보겠습니다.

save()와 saveAll() 둘다 @Transaction이 적용되어 있습니다.
차이점은 save()는 외부에서 1번씩 호출하지만, saveAll () 은 같은 인스턴스 내의 메소드인 save() 를 호출합니다.
save 함수를 호출하는 개수는 같은데 왜 성능상 차이가 날까요?
이유는 프록시를 태우는 횟수가 다르기 때문입니다.
public interface CustomeRepository extends JpaRepository<Entity, Integer> {
}
JpaRepository를 상속하여 정의하는 Custom Repository Interface는 Spring Data JPA가 런타임에 프록시를 생성합니다.
개발자가 해당 Interface를 사용하면 프록시를 태우게 됩니다.
이 프록시는 내부적으로 SimpleJpaRepository의 인스턴스를 사용하여 데이터베이스와의 상호작용을 처리합니다.
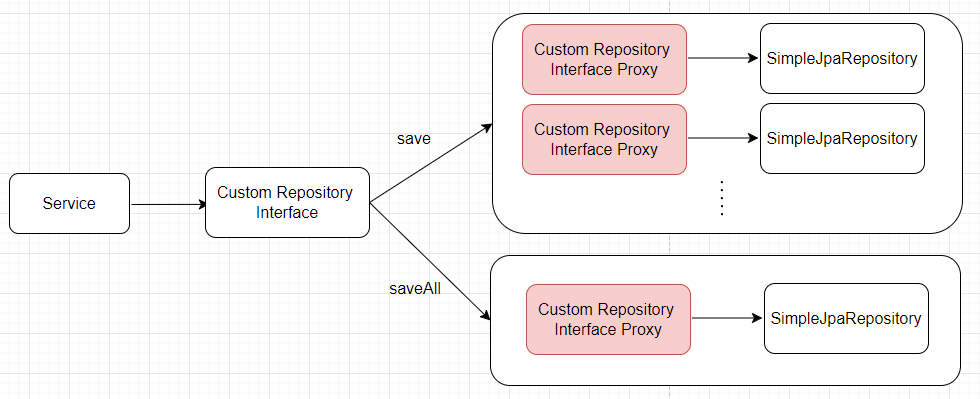
save()와 saveAll()이 모두 단일 트랜잭션으로 묶여 있더라도 save()를 호출한 수만큼 Custom Repository Interface의 프록시를 타게 되며, saveAll()은 Custom Repository Interface의 프록시를 한번만 탄 후에 save()를 내부 함수로 호출하여 프록시를 태우는 비용이 발생하지 않습니다.
참고
https://maivve.tistory.com/342
https://thorben-janssen.com/spring-data-jpa-save-saveandflush-and-saveall/
'Tech > JPA' 카테고리의 다른 글
| Jpa로 데이터 수정 작업 후 수정된 데이터를 카프카에 전송하는 방법 (1) | 2023.02.11 |
|---|---|
| detached entity passed to persist 에러 (1) | 2021.12.01 |